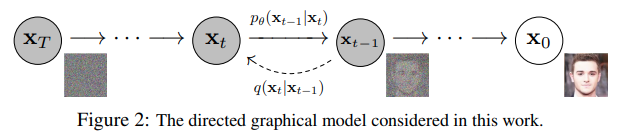
The essential idea is to systematically and slowly destroy structure in a data distribution through an iterative forward diffusion process which is fixed.
We then learn a reverse diffusion process that restores structure in data, yielding a highly flexible and tractable generative model of the data.
Does it look like a Autoencoder approach?
DALLE2, MidJourney, Disco Diffusion, Stable Diffusion, Imagen are build on top of diffusion model.
DALLE1 is a Auto-regressive model.
In terms of photo-realism outputs, Diffusion models are better than GANs.
Note: It is better if you understand VAE before studying Diffusion.
A (denoising) diffusion model is a neural network that learns to gradually denoise data starting from pure noise.
The set-up consists of 2 processes:
Forward (Fixed)
Forward diffusion process q : Gradually (regulated by a schedule) adds noise (sampled from a normal distribution) to an image until become pure noise
different amount of noise are applied in each timestep according to the schedule (different mean and variance)
Reverse (Has to been Learned)
A Learned reverse denoising diffusion process pθ : a neural network is trained to gradually denoise (remove a step of noise in each pass.) an image from pure noise to actual image.
By doing so, we can start with a completely random noise and let the model remove noise until we have a new image.
It’s a markov chain because it’s a sequence of stochastic events where each timestep depends on the previous timesteps.
Note the latent states have the same dimensionality as the input image.
Training algorithm of DDPM
1: x0∼q(x0): take a random sample x0 from the real unknown and possibiliy complex data distribution q(x0)
2: t∼Uniform({1,…,T}) : sample a noise level t uniformally between 1 and T (i.e., a random time step)
3: ϵ∼N(0,I) : sample some noise (has same dimensionality as input data) from a gaussian distribution and corrupt the input by this noise at timestep t , using the reparameterization trick αˉtx0+1−αˉtϵ
4: give the generated sample to the neural network to predict the noise based on the corrupted image xt and train the network
5: 1-4 are done on batches of data and optimize the network.
Something Important:
Paper used T = 1000 (timestep = 1000), but the follow up papers are able to decrease this number.
Images are scaled to inbetween [-1, 1] as to have the same range as the prior of a standard normal distribution p(xT)∼N(0,1) centered at 0 with variance of 1.
Inference algorithm of DDPM (Denoising)
As mentioned, generating new images from a diffusion model happens by reversing the diffusion process: we start from T, where we sample pure noise from a Gaussian distribution, and then use our neural network to gradually denoise it (using the conditional probability it has learned), until we end up at time step t=0. By predicting the noise in each denoising step, we can get the less noisy image xt−1 by predicting the mean and variance of the noise.
Ideally, we end up with an image that looks like it came from the real data distribution.
1: xT∼N(0,I): Draw samples from normal distribution N(0,I)
2: for t=T,…,1: for reverse timestep T to 1, at every step
3: draw white noise z from normal distribution
If t=1, we need not to add noise anymore.
4: Forming new sample with the mean of denoising model αt1(xt−1−αˉt1−αtϵθ(xt,t)) and then add the white noise z rescaled with standard deviation σt.
DDPM From Math Perspective
Both the forward and reverse process are indexed by t happen for some number of finite time steps T.
Start with t=0, sample a real image x0 from image distribution and apply some noise from a Gaussian distribution at each time step t, which is added to the image of the previous time step t−1.
x1 will be 1st iteration of noise applied, x42 will be 42th iteration of noise applied… The last step will be xt.
Given a large enough T, a well behaved schedule for adding noise at each time step, we get an isotropic Gaussian distribution at t=T via a gradual process. (Isotropic means it looks the same in every direction)
We define function for Forward diffusion process q(xt∣xt−1) which means given an image with less noise at timestep t−1, we derive the image with little bit more noise at timestep t.
Then we also define function for reverse denoising diffusion process pθ(xt−1∣xt) which means given an image with more noise at timestep t, we derive the image with less noise at timestep t−1. it is done by predicting the noise that was added to the image.
Forward Diffusion Process
From x0 input image to a noisy version image at timestep t, it can be formulated as:
q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
The single forward diffusion process q(xt∣xt−1) can be formulated as N(z;μ,σ):
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
where
N is the normal distribution
xt is the output
1−βtxt−1 is the mean
βtI is the variance
β is the scale at schedule
This means the sample xt is obtained by scaling the previous sample xt−1 with 1−βt according to a variance schedule, then add independent and identically distributed Gaussian noise with square root of variance βt at timestep t.
xt=1−βtxt−1+βtϵ
where ϵ∼N(0,I) => sample from gaussian noise
DDPM used the linear schedule such that it will looks like this:
In later papers, Cosine schedule is used to replace linear schedule
Linear approach is sub-optimal because the last couple of timesteps already seems like complete noise and might be redundent. On the other hand, the information is destroyed too fast.
Cosine schedule solves both problems of the linear schedule
Since sum of gaussians is still a gaussian distribution, To apply multiple steps in one step, we can define:
αt=1−βt
αˉt=∏s=1tαs
Therefore at t=4, α4=α1⋅α2⋅α3⋅α4
Using the Reparameterization Trick N(μ,σ2)→μ+σ⋅ϵ,
We get q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)=1−βtxt−1+βtϵt−1
Sub αt=1−βt into the formula, we get
xt=1−βtxt−1+βtϵ=αtxt−1+1−αtϵt−1.
Given xt−1=αt−1xt−2+1−αt−1ϵt−2
We can represent xt as αtαt−1xt−2+1−αtαt−1ϵˉt−2 , where ϵˉt−2 merge the two gaussians.
# Get the indexed term from the list # https://github.com/pytorch/pytorch/issues/15245 Gather backward is faster than integer indexing on GPU defextract(a, t, x_shape): batch_size = t.shape[0] out = a.gather(-1, t.cpu()) return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
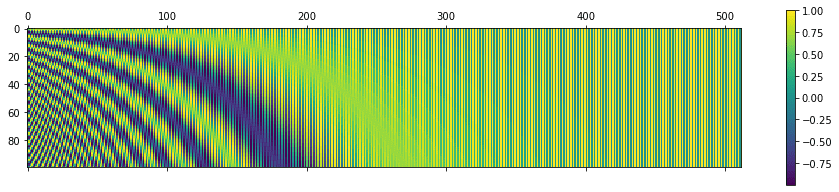
At small t, most of the low frequency contents are not perturbed by the noise, but high frequency content are being perturbed.
At bigger t, low frequency contents are also perturbed.
At the end of forward process, we get rid of the both low and high frequency contents of image.
Parametrized Reverse Denoising Diffusion Process
To reverse the process, the intuitive idea is to find q(xt−1∣xt).
However, q(xt−1∣xt)∝q(xt−1)q(xt∣xt−1) is intractable. Instead, we can approximate q(xt−1∣xt) using a Normal distribution if βt is small in each forward diffusion step.
Generating new images from a diffusion model happens by reversing the diffusion process: we start from T, where we sample pure noise from a Gaussian distribution, and then use our neural network to gradually denoise it (using the conditional probability it has learned), until we end up at time step t=0. Ideally, we end up with an image that looks like it came from the real data distribution.
From pure noise / noisy image xt to original image x0 or less noisy image at timestep t, it can be formulated as:
pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)
p(xT)=N(xT;0,I)
The single reverse denoising diffusion process p(xt−1∣xt) can be formulated as N(z;μ,σ):
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
where
N is the normal distribution
μθ parametrize the mean
∑θ parameterize the variance
We can derive a slightly less denoised image xt−1 by plugging in the reparametrization of the mean and variance.
We need a trainable neural network to represent a (conditional) probability distribution of the backward process. We want to learn 2 parameters:
a mean parametrized by μθ(xt,t)
a variance parameterized by Σθ(xt,t)
However, DDPM authors decided to keep the variance fixed, and let the neural network only learn (represent) the mean μθ of the conditional probability distribution.
p(xt−1∣xt)=N(xt−1;μθ(xt,t),βtI)
where a linear schedule is used
Later in the Improved diffusion models paper, a neural network also learns the variance of this backward process, besides the mean.
By predicting the mean of noise, we can know the Noise of the image.
In order to get the exact image, we simply get xt−1≈xt−noise.
# Get the indexed term from the list # https://github.com/pytorch/pytorch/issues/15245 Gather backward is faster than integer indexing on GPU defextract(a, t, x_shape): batch_size = t.shape[0] out = a.gather(-1, t.cpu()) return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
@torch.no_grad() defp_sample(model, x, t, t_index): """ Sample from the model. Mean is predicted, Variance is fixed in this example """ betas_t = extract(betas, t, x.shape) sqrt_one_minus_alphas_cumprod_t = extract( sqrt_one_minus_alphas_cumprod, t, x.shape ) sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape) # Use our model (noise predictor) to predict the mean model_mean = sqrt_recip_alphas_t * ( x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t )
b = shape[0] # start from pure noise (for each example in the batch) img = torch.randn(shape, device=device) imgs = [] for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps): img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i) imgs.append(img.cpu().numpy()) return imgs
b = shape[0] # start from pure noise (for each example in the batch) img = torch.randn(shape, device=device) imgs = [] final_img = None for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps): img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i) final_img = img.cpu().numpy() return final_img
Recall what we understood in the forward process. In large timesteps, the low frequency components are hidden, and in less timestep, the high-frequency contents are hidden.
Therefore, in the reverse process, we can make a trade-off between content detail with the weighting.
Low frequency content responses to the main content of the image
High-frequency content responses to the low-level fine details
Therefore the noise schedule can play a huge role here.
Objective function of Diffusion
The loss function is simply the negative log likelihood
−log(pθ(x0))
However, pθ(x0) is not nicely computable as it depend all other timesteps coming before x0 (i.e. xT,...,x1)
As a solution we can compute the variational lower bound, that is commonly used for training Variational Autoencoder. We write this formula:
By the bayes rule q(xt∣xt−1)=q(xt−1)q(xt−1∣xt)q(xt) , we get the three terms with high variance (We dont know where the noise image came from). Therefore we could reduce the variance by conditioning x0 (Given the initial noise-free picture) such that q(xt−1)q(xt−1∣xt)q(xt)⇒q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0)
Plugging this term q(xt∣xt−1)=q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0) into −log(p(xT))+∑t=2Tlog(pθ(xt−1∣xt)q(xt∣xt−1))+log(pθ(x0∣x1)q(x1∣x0)), We have
Note the first term DKL(q(xT∣x0)∣∣p(xT)) can be dropped because it has no learnable parameters, and the term will be small. It is simply the KL divergence from the diffusion kernel in the last step (xT∣x0) to the base distribution xT. The (xT∣x0) is converge to a standard normal distribution, which is the same distribution as xT. Therefore after dropping the first term we have:
Which are completely the same except the epsilon term. Through simplification, we get
Lt−1=2σt2αt(1−α^t)βt2∣∣ϵ−ϵθ(xt,t)∣∣2
we can replace the scalar term with a time dependant lambda value:
Lt−1=λt∣∣ϵ−ϵθ(xt,t)∣∣2
where the time dependant λt ensures that the training objective is weighted properly for the maximum data likelihood training. However, this weight is often very large for small t 's, and very small for large t’s.
… And then the author found out ignore the scaling term (put λt=1) would result a better quality. Therefore we get:
Lt−1=∣∣ϵ−ϵθ(xt,t)∣∣2
Replugging the term into ∑t=2TDKL(q(xt−1∣xt,x0):
LVLB=t=2∑T∣∣ϵ−ϵθ(xt,t)∣∣2−log(pθ(x0∣x1))
As at sampling time t=1 we dont noise to it, we can drop the −log(pθ(x0∣x1) term as well So Finally:
Lsimple=Et,x0,ϵ[∣∣ϵ−ϵθ(xt,t)∣∣2]
So that’s way basically in implementation, we want to compute a MSE loss (or any loss) between the real noise and the predicted noise.
if loss_type == 'l1': loss = F.l1_loss(noise, predicted_noise) elif loss_type == 'l2': loss = F.mse_loss(noise, predicted_noise) elif loss_type == "huber": loss = F.smooth_l1_loss(noise, predicted_noise) else: raise NotImplementedError()
return loss
Components of a Diffusion model
We will need mainly 3 components:
A UNet model that predicts the noise in an image
Noise Scheduler that sequentially adds noise
A way to encode the current timestep
Generally we want to use a network that is similar to Autoencoder. we want to have “bottleneck” layer in between the encoder and decoder. The encoder first encodes an image into a smaller hidden representation called the “bottleneck”, and the decoder then decodes that hidden representation back into an actual image. This forces the network to only keep the most important information in the bottleneck layer.
DDPM authors used a U-Net, similar to an unmasked PixelCNN++ with group normalization throughout
bottleneck, residual connections between encoder and decoder (greatly improving gradient flow)
Attention, ConvNext
Sinusoidal embedding from Transformer is used to project into each residual block because to create a denoising schedule that match the noising schedule in the forward process
UNet is a segmentation network that gives an output dimension same as input dimension.
The model take a noisy image with 3 color channels as inputs, and predict the noise in the image
That means the model learns the mean (and variance) of the gaussian distribution of the images
Known as denoising score matching
Timestep encoding is used to encode the timestep such that the model knows which timestep it is in.
To encode the timestep, we can use sinusoidal embedding (hand-crafted) or some other positional embeddings (learned from data)
The key idea is that each position has a unique positional vector