Variational autoencoders (VAEs) belong to the families of variational Bayesian methods. Despite the architectural similarities with basic autoencoders, VAEs are architecture with different goals and with a completely different mathematical formulation. The latent space is in this case composed by a mixture of distributions instead of a fixed vector.
Pθ(x)=Pθ(z∣x)Pθ(x∣z)p(z)
where
Pθ(x∣z) is the likelihood
p(z) is the prior
Pθ(z∣x) is the posterior
We want to perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions.
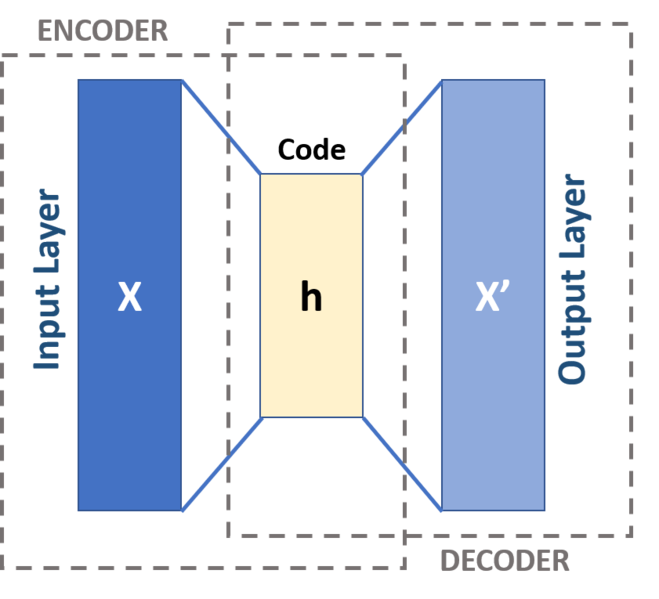
AutoEncoder (AE)
The idea of AutoEncoder (AE) is to compress the information into code and then decompress it.
However AutoEncoder itself is deterministic, which does not generate a new sample.
Variational AutoEncoder (VAE)
The idea of Variational AutoEncoder is to map a distribution into the latent space and then randomly sample it, which is stochastic.
We compress the images into latent space, then we sample the output from a conditional distribution.
We have:
qϕ(z∣x) as a probabilistic encoder
pθ(x∣z) as a probabilistic decoder
Variational bound
The marginal likelihood is composed for a sum over the marginal likelihoods of N individual datapoints logpθ(x(1),...x(N))=∑i=1Nlogpθ(x(i)), which can each be rewritten as a KL divergence of the approximate from the true posterior:
We want to differentiate and optimize the lower bound L(θ,ϕ;x(i))with respect to both the variational parameters ϕ and generative parameters θ.
Eqϕ(z∣x(i))[logpθ(x(i)∣z)] is basically the reconstruction loss
−DKL(qϕ(z∣x(i))∣∣pθ(z)) is the regularizer
The Reparameterization Trick
Basically, the trick is very simple.
The core idea is that
Noise is separately generated such that z=gϕ(ϵ,x)
ϵ is an auxiliary variable with independent marginal p(ϵ)
gϕ(.) is some vector-valued function parameterized by ϕ
E.g. The univariate Gaussian case:
z∼p(z∣x)=N(μ,σ2)→z=μ+σ⋅ϵ
where → is the Reparameterization Trick
ϵ is an auxiliary noise variable ϵ∼N(0,1).
1 2 3 4 5 6 7 8 9 10 11
defreparameterize(self, mu: Tensor, logvar: Tensor) -> Tensor: """ Reparameterization trick to sample from N(mu, var) from N(0,1). :param mu: (Tensor) Mean of the latent Gaussian [B x D] :param logvar: (Tensor) Standard deviation of the latent Gaussian [B x D] :return: (Tensor) [B x D] """ std = torch.exp(0.5 * logvar) eps = torch.randn_like(std) return eps * std + mu
The Encoder takes the input image (flattened) and gives two output (mu, log_var) of same dimensions.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defencode(self, input: Tensor) -> List[Tensor]: """ Encodes the input by passing through the encoder network and returns the latent codes. :param input: (Tensor) Input tensor to encoder [N x C x H x W] :return: (Tensor) List of latent codes """ result = self.encoder(input) result = torch.flatten(result, start_dim=1)
# Split the result into mu and var components # of the latent Gaussian distribution mu = self.fc_mu(result) log_var = self.fc_var(result)
The Decoder simply turn the latent variable z back to the reconstructed image.