
DreamBooth, Textual Inversion, LoRA
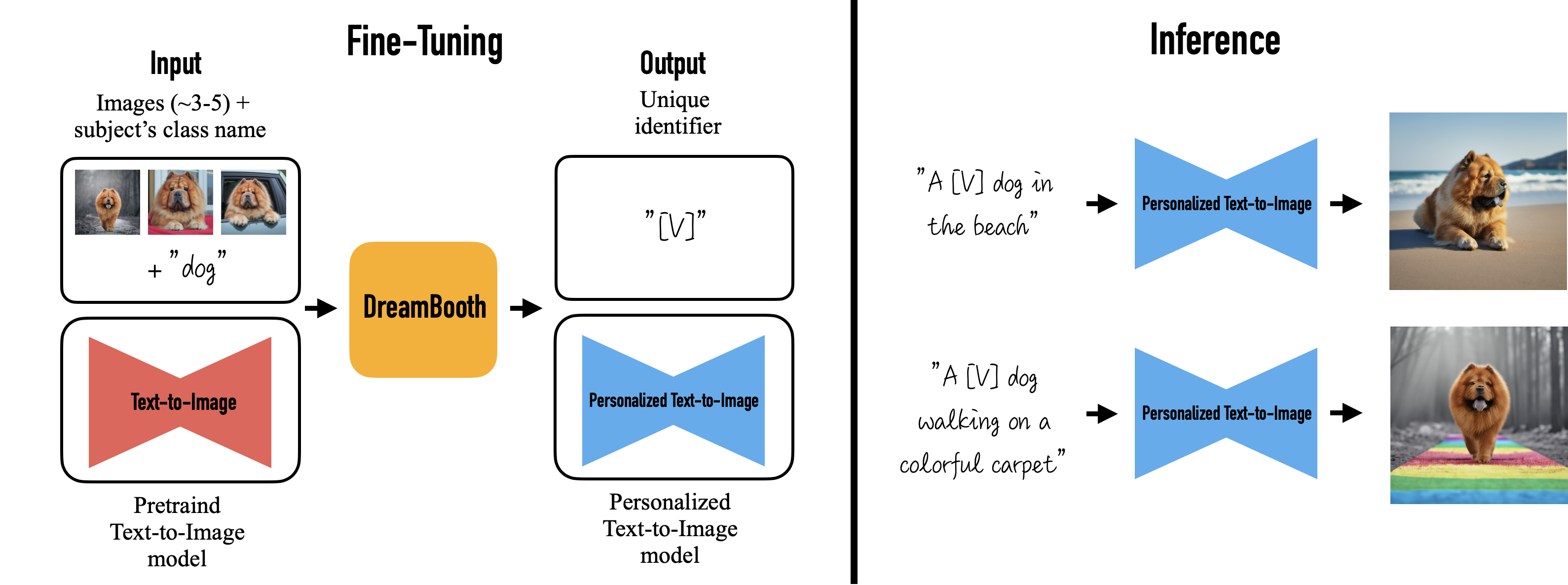
DreamBooth
Paper: DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation

- Given only a few (typically 3-5) casually captured images of a specific subject, without any textual description, our objective is to generate new images of the subject with high detail fidelity and with variations guided by text prompts.
DreamBooth : The Model is finetuned
- +ve : most effective
- -ve : storage inefficient because new model is trained
- Output size around 2000MB
Method
Personalization of Text-to-Image Models
- Exploiting the ability of large text-to-image diffusion models
- seem to excel at integrating new information into their domain without forgetting the prior or overfitting to a small set of training images

Designing Prompts for Few-Shot Personalization
- implant a new (unique text identifier, image object) pair into the diffusion model’s dictionary
- unique text identifier is a rare identifier that contain random characters; e.g. “xxy5syt00”.
Class-specific Prior Preservation Loss
- The best results for maximum subject fidelity are achieved by fine-tuning all layers of the model.
- This includes fine-tuning layers that are conditioned on the text embeddings
Checkout LoRA + DreamBooth
- Language drift
- an observed problem in language models
- a model that is pre-trained on a large text corpus and later fine-tuned for a specific task progressively loses syntactic and semantic knowledge of the language
similar phenomenon happen in diffusion models finetuning
- Reduced output diversity
- When fine-tuning on a small set of images we would like to be able to generate the subject in novel viewpoints, poses and articulations
- diversity is lost when the model is trained for too long
Class-specific prior preservation loss
- encourages diversity
- counters language drift
To mitigate the two aforementioned issues, we propose an autogenous class-specific prior preservation loss that encourages diversity and counters language drift. In essence, our method is
- to supervise the model with its own generated samples, in order for it to retain the prior once the few-shot fine-tuning begins.
This allows it to generate diverse images of the class prior, as well as retain knowledge about the class prior that it can use in conjunction with knowledge about the subject instance.
Orginally the diffusion model is train by the loss:
with Class-specific prior preservation loss, Therefore the new loss for finetuning:
Implementation:
1 | #https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py#LL1001C1-L1015C92 |
Metrics
DINO-Fidility
- Our proposed DINO metric is the average pairwise cosine similarity between the ViT-S/16 DINO embeddings of generated and real images.
- This is our preferred metric, since, by construction and in contrast to supervised networks, DINO is not trained to ignore differences between subjects of the same class. Instead, the self-supervised training objective encourages distinction of unique features of a subject or image.
1 | # Helper code |
Textual Inversion
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Key ideas:
- Distill only a few (3 to 5) images into input token embeddings
- e.g. 3 cat images become a token
<cat>
- e.g. 3 cat images become a token
- Model weights itself is frozen and remains unchanged
- Gradient update is performed on the token vector instead of the model
Basically: The idea assumed that the model already understand the concept. We just need to find the “right input vector”.



Method
- The idea assumed that the model already understand the concept. We just need to find the “right input vector”.
- Gradient update is performed on the token vector S* instead of the model
- The output is the S* embedding (light-weight tiny embedding)
- Output size ~ 0.013MB

LoRA
LoRA: Low-Rank Adaptation of Large Language Models
- Introduce new weights to the model
- Insert new layers between the model intermediate states
- Only new layers are trained, other weights are frozen
- Teaching the model a new concept without finetuning the whole model
- much faster training
- Note that LoRA generates a small file that just notes the changes for some weights in the model.
- Output size around 145MB
Originally LoRA was used in large language model, but now it is also used in diffusion model for image generation
- Adds a tiny number of weights to the diffusion model and trains the layers until the modified model understands the concept
LoRA in Stable Diffusion

LoRA applies small changes to the most critical part of Stable Diffusion models: The cross-attention layers. It is the part of the model where the image and the prompt meet.





