Paper Review - Diffusion Models Applications
Diffusion Models Applications
Image Synthesis, Text-to-image, Controllable Generation
Text-to-image
- Inverse of image captioning problem
- Conditional generation: given a text prompt , generate high-res images .
Text-to-image: GLIDE
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models: https://arxiv.org/abs/2112.10741
Main contribution:
- A 64x64 base model + a 64x64 to 256x256 super-resolution model
- Tried classifier-free and CLIP guidance, finding that classifier-free guidance works better than CLIP guidance.
CLIP
Learning Transferable Visual Models From Natural Language Supervision: https://arxiv.org/abs/2103.00020

- CLIP (Contrastive Language–Image Pre-training) model contains two componts:
- Image Encoder
- Text Encoder
During training of CLIP, batch of caption pairs are sampled from a large dataset.
The model optimize a contrastive cross-entropy loss which encourages high dot product value between Image Encoder and Text Encoder if image and caption are from the same pair. Low dot product if image and caption are from the different pair. Formulated as:
The optimal value of the dot product, should be:
CLIP Guidance : Replace the classifier in classifier guidance with CLIP model
Given the formula above, we can use the CLIP model as a classifier guidance.
Recall in the classifier guidance, we sample with a modified score:
We augment the second term to fit our CLIP model . Note when we take gradient over , the term will disappear.
Then we basically modify the score function
However in GLIDE they showed that classifier-free guidence is better
Text-to-image: DALL-E 2
https://openai.com/dall-e-2/
Hierarchical Text-Conditional Image Generation with CLIP Latents: https://arxiv.org/abs/2204.06125Note that DALL-E 1 was an autoregressive transformer model.
- 1kx1k Text-to-image generation model
Main Idea:
- Built up on a pre-trained CLIP model
- Grab text embedding from the pretrained CLIP embedding then frozen
- Next, use a prior model then decoder model as a pipeline
- Prior model: produces CLIP image embeddings conditioned on the input caption
- Option 1: Autoregressive prior: quantize image embedding to a sequence of discrete codes and predict them autoregressively
- Option 2 (better): Diffusion Prior: model the continuous image embedding by diffusion models conditioned on caption
- Decoder: produce image conditioned on the CLIP image embedding and text
- Cascaded diffusion model: 1 base model (64x64), 2 super-resolution models (64x64 -> 256x256, 256x256->1024x1024)
- Largest super-resolution model trained on patches of 1/4 size, takes full-res inputs at inference time
- Classifier-free guidance & noise conditioning augmentation are important
- Cascaded diffusion model: 1 base model (64x64), 2 super-resolution models (64x64 -> 256x256, 256x256->1024x1024)
- Prior model: produces CLIP image embeddings conditioned on the input caption
Why conditional the decoder on the CLIP image embedding?
- CLIP Image embeddings capture high-level semantic meaning; latents in the decoder model take care of the low-level details
- The bipartite latent representation of the CLIP image embeddings enable serveral text-guided image manipulation tasks
Bipartite latent representations
Given an input image, we can get the bypass latent representation known as Bipartite latent representations
it contains
- is the CLIP image embeddings, can be derived by running the clip image encoder
- is the latents in the decoder which can be derived by running inversion of DDIM sampler for decoder
Paper shows that it is possible to run the decoder and get near exact reconstruction of the input image
Some interesting examples using the Bipartite latent representations
- DALL-E 2 Image variations
- Generate image variations given the input image
- Fix the CLIP embedding while decode using different decoder latents $
- DALL-E 2 Image interpolation
- Interpolate any two images
- Interpolate image CLIP embedding , use different to get different interpolation trajectories
- DALL-E 2 Text Diffs
- Edit the image towards a different prompt given the input image and the caption
- Change the image CLIP embedding towards the difference of the text CLIP embeddings of two prompts, while decoder latent is kept as a constant
Text-to-image: Imagen
https://imagen.research.google/
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding: https://arxiv.org/abs/2205.11487
- 1kx1k Text-to-image generation model
Highlight:
- Photorealism; SOTA automatic scores (FID scores) and human ratings
- Deep level of language understanding to the prompts
- So simple that it does not involve latent space and have no quantization
- DrawBench: a new benchmark for text-to-image evaluations
- a set of 200 prompts to evaluate text-to-image models across multiple dimensions
Key modeling components of Imagen
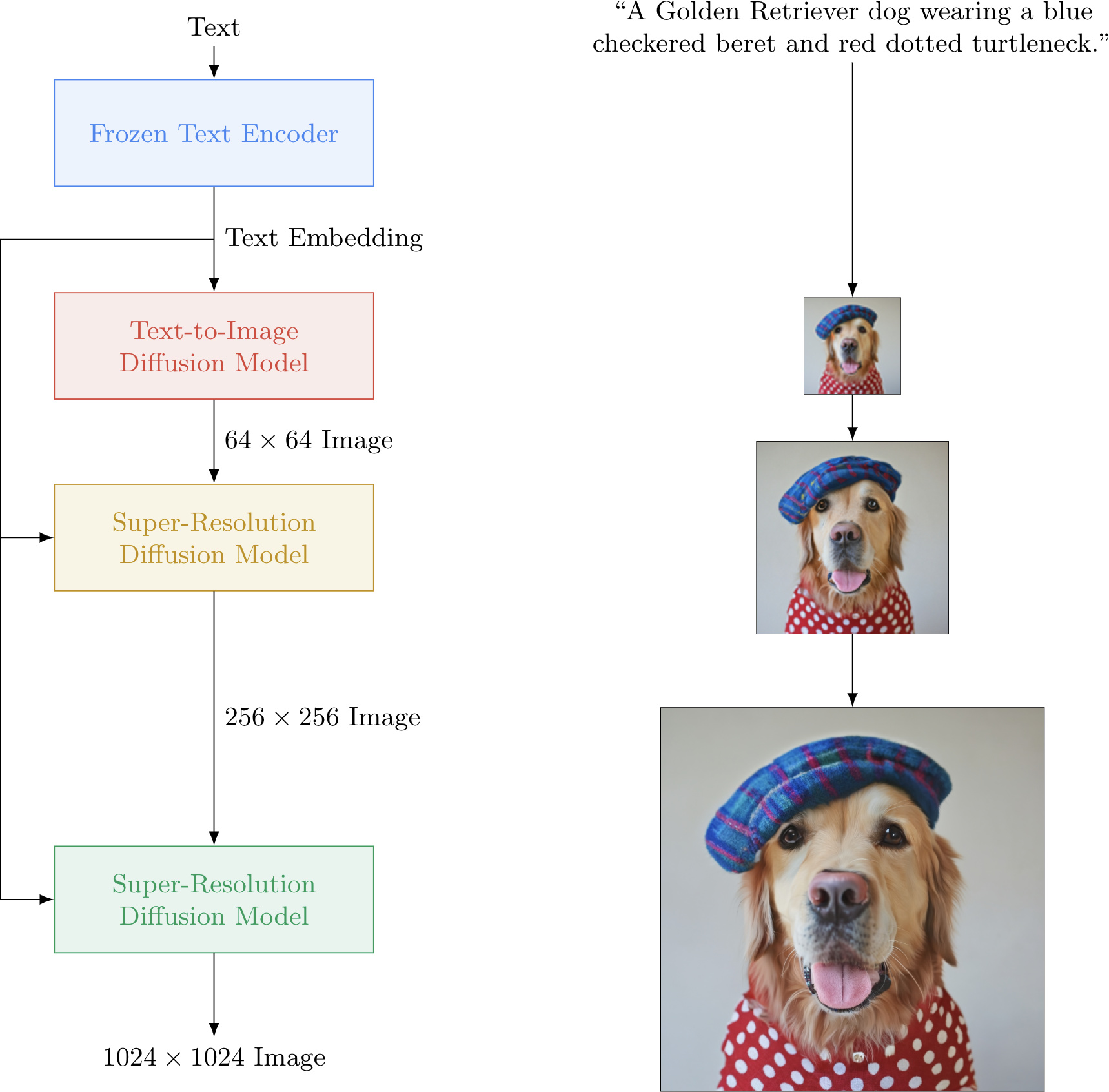
- Cascaded diffusion models
- Classifier-free guidance
- Dynamic thresholding
- Frozen large pretrained language models as text encoders. (T5-XXL)
Key observations:
- Beneficial to use text conditioning for all super-res models
- Noise conditioning augmentation weakens information from low-res models, thus need text conditioning as extra information input
- Scaling text encoder is extremely efficient in terms of improving performance
- More important than scaling diffusion model size
- Human raters prefer T5-XXL as the text encoder over CLIP encoder on DrawBench
Dynamic thresholding
- New technique introduced by Imagen
When using large classifier-free guidance weights, although it gives better text alignment, it gives worse image quality (higher FID score).
- Hypothesis: at large guidance weight, the generated images are saturated due to the very large gradient updates during sampling
- Solution: dynamic thresholding: adjusts the pixel values of samples at each sampling step to be within a dynamic range computed over the statistics of the current samples
- Static thresholding => image look saturated
- Dynamic thresholding => image look less saturated and more realistic
Controllable Generation: Diffusion Autoencoders
Diffusion Autoencoders: Toward a Meaningful and Decodable Representation https://arxiv.org/abs/2111.15640
Learning semantic meaningful latent representations in diffusion models
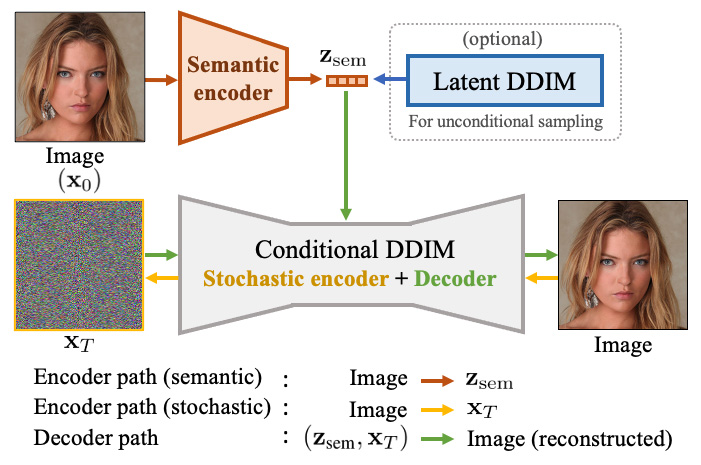
- is the inversion of the DDIM sampler which capture low-level stochastic variations of the images
- by assuming a low dimensional semantic latent they are able to learn different semantic meanings
Image Editing, Image-to-Image, Super-resolution, Segmentation
Super-Resolution: SR3
https://iterative-refinement.github.io/
Image Super-Resolution via Iterative Refinement https://arxiv.org/abs/2104.07636
- Image super-resolution can be considered as training where
- = low-resolution image
- = high-resolution image
Train a score model for conditioned on using
- where L1 norm give better diversity, L2 norm give better quality
The conditional score is simply a U-Net with and concatenated
Image-to-Image Translation: Palette
Palette: Image-to-Image Diffusion Models https://arxiv.org/abs/2111.05826
Many Image-to-image translation applications can be considered as training where
- is the input image
- is the target
Train a score model for conditioned on using
The conditional score is simply a U-Net with and concatenated
- Works on Colorization, Uncroping
- Assume you have Paired access of the input and output data
Conditional Generation: ILVR
ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models: https://arxiv.org/abs/2108.02938
Iterative Latent Variable Refinement
A simple technique to guide the generation process of an unconditional diffusion model using a reference image
- Given the conditioning (reference) image the generation process is modified to pull the samples towards the reference image.
- Modify the reverse denoising process
Semantic Segmentation
Label-Efficient Semantic Segmentation with Diffusion Models https://arxiv.org/abs/2112.03126
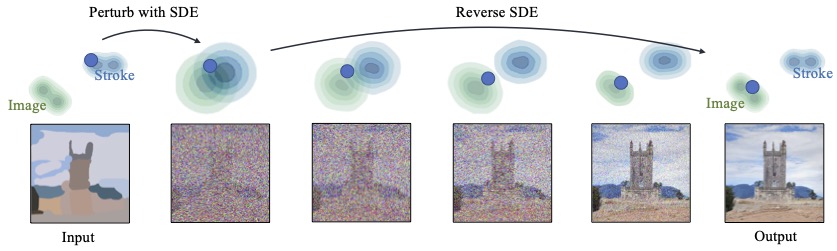
Image Editing: SDEdit
https://sde-image-editing.github.io/
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations https://arxiv.org/abs/2108.01073

- Forward diffusion brings two distributions close to each other