
Some Practice Questions on DNN
Deep Learning Basics
Are deep learning and deep neural networks the same thing?
No
What is the relationship between deep learning and machine learning?
Deep learning is a kind of machine learning
The weight connecting artificial neurons of a neural network represents the strength of the signal passing between biological neurons. Is it true?
True
Will close-form solution work in gradient-based methods?
If there is a closed form solution for the derivative of the loss function, we can simply find the weights by solving equations, that is called the close-form solution.
However, in practice, the relationship between the loss function and the network weights is very complex. Setting the derivative to zero will not lead to a closed-form solution.


(a)(i)
- Number of Inputs: 28x28 = 784
- Number of outputs: 10
(a)(ii)
The bias terms are to allow the network to produce decision boundaries that lie on any regions of the feature space, not necessarily passing through the origin.

- Activation function: Softmax
- let the network produce posterior probabilites of individual classes
- Objective function: Cross-entropy
- the function is differentiable and is closest to the classification error. It also emphasizes the error on the correct class

If all hidden nodes are linear, the multiple layers reduce to a single layer and the advantages of deep architecture is lost. Mathematically, denote as the input and as the weights (including bias terms) of the hidden layers. When all hidden neurons are linear, then the network outputs become
where . This is equivalent to multi-class logistic regression.
Model Capacity (Concept)

When gradient vanishing is not an issue and that the amount of training data is very large, a deep neural network can provide more abstract representation of the features. The degree of abstraction increases from the bottom layers to the upper layers. Very abstract features are close to the classification task, making classification easy. In fact, if the features are abstract enough, a linear layer with a softmax output can readily classify the highly abstract features. For example, in face recognition, a deep network with sufficient layer can represent different types of faces (e.g., large eyes, big nose, big eyebrow, etc.) in the last hidden layer, making the softmax layer to be able to classify the face easily. On the other hand, the hidden layers in a shallow network can only represent some primitive features of the faces (e.g., round edge, sharp edge, round hole, etc.), making classification difficult.
Can deep neural networks be used as feature extractor?
Yes
Model Hidden Layer (Concept)

5a)
As shown in the above figure, the outputs of the hidden nodes are a function of the linear weighted sum of inputs plus a bias. If the sigmoid function f() has a steep sloop, its output over a range of input x1 and x2 will look like the following figure. The left and right figures correspond to the output of hidden neurons 1 and 2, respectively. The first neuron maps data above L1 to 0.0 and below L1 to 1.0. Similarly, the second neuron maps data above L2 to 1.0 and below L2 to 0.0. The resulting mapping are shown in the bottom figure. The output neuron separates the data in the 2-D space defined by the hidden node outputs (and ). As can be seen, the data on this new space are linearly separable and can be easily classified by L3, which is produced by the output neuron.

5b)

Optimization
SGD and Momentum (Concept)

Revisit:
Gradient Decent
- Use all samples to calculate derivatives for each step
- Too expensive when the sample size is big
Stochastic Gradient Decent
- Randomly pick one sample to calculate derivatives for each step
- Save computation (update the parameters with just the new data)
- Easily to update parameters when new data shows up
Mini-batch Gradient Decent:
- Randomly pick a small subset of samples to calculate derivatives for each step
- Save computation

But we can see:
Stochastic or Mini-Batch Gradient Descent, the points in training steps are oscillating.
For Gradient Descent, Oscillation problem could also exist when there is a large learning rate.

Oscillation means the point landed on unintended regions of the error surface.
The momentum is designed to minimize the oscillation. With momentum, ends up eventually taking steps with much smaller oscillation.
Formula of Gradient Descent without momentum
the weights at the t-th update (not epoch) are changed according to the gradient with respect to the weights as follow:
Formula of Gradient Descent with momentum
the weights at the t-th update (not epoch) are changed according to the gradient with respect to the weights as follow:
With the momentum term is now pointing to a direction between the current gradient and the previous update, as shown in the figure below.

Therefore, the update path will become closer to the ideal path as shown below.
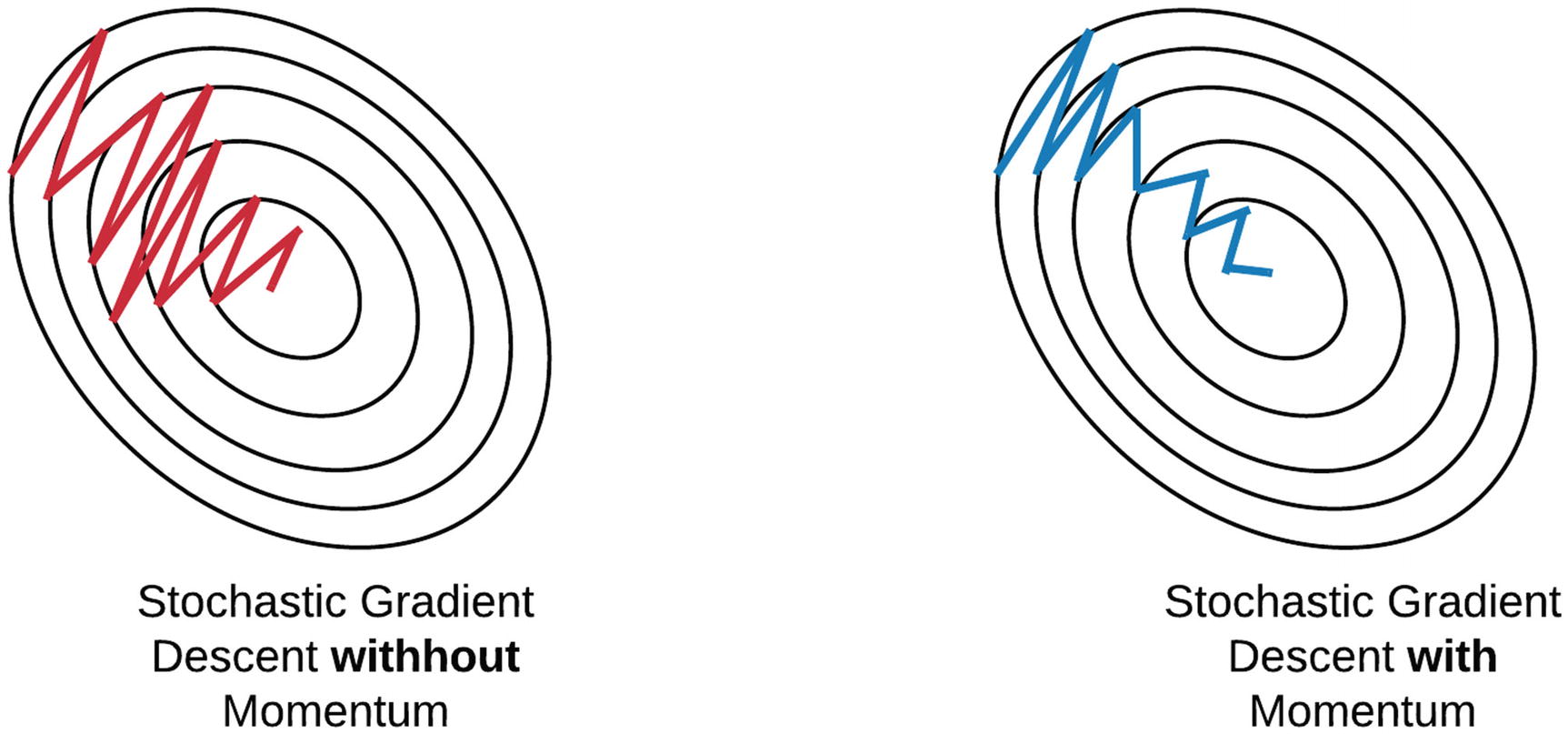
When the error surface is symmetric across all dimensions, the momentum term still plays a role in stochastic gradient descent. Is this true?
True.
When the error surface is symmetric across all dimensions, the gradient update won’t encounter situation like the direction update.
However, it will encounter the situation when it overshoots the minimum point, so the momentum will helps the update and correct the update direction. Therefore, the momentum term still plays a role.


Gradient Decent (Math Derivation)

Loss function Binary Cross-Entropy (Ignored index for simplicity):
Note the derivative of sigmoid:
If
then,
First we define the forward propagation.
Output layer
The first hidden layer
And now we know depends all the terms, and depends all the terms.

Now we can find the gradients with respect to the weights at the first hidden layer:
Note the derivative of is
Find the derivative of Loss function BCE:
Therefore the derivative of BCE =
So we know that
and since
Therefore:
^we can throw away the scale
Plugging back the numbers, we found the gradient of first hidden layer.
Now we can find the gradients with respect to the weights at the input layer:
Since
and Since
So
Plugging back the numbers, we found the gradient of first hidden layer.
Therefore the update formula:
Gradient Decent (Math Derivation + Concept)


First we define the forward propagation.
Softmax Layer (Output after activation):
The Layer2 (Output before activation) ( is the index number across the layer):
An example (k=1):

The Layer1 ( is the index number across the layer):
where
Consider the and the loss function, we have:
Equation 1:
Equation 2 Categorial Cross-Entropy (Ignored index for simplicity):
And now we know depends all the terms, and depends all the terms.
Now we know the gradients with respect to the weights at Layer 2 are:
So we start to compute the back propagation from the final layer:
Break down the summation into two parts, one part , another part
Note the derivative of is
Find the derivative of Loss function CCE:
Therefore the derivative of CCE =
so we expend the derivative of :
Note:
Because depends on where , we need to compute the derivative of w.r.t. , i.e.,
where
So we can know
And if . if .
Therefore:
Since ,
Therefore, the gradients with respect to the weights at Layer 2 are:
Since
compute derivative
Therefore
How about the first layer weights?

The gradients with respect to the weights at Layer 1 are:
find the term :
Note the derivative of sigmoid:
If
then,
So the term
Therefore:
and the update formulae:
Note that for sigmodial non-linearity, we have
Because , and involves the multiplication of more terms with absolute value less than , it is likely be smaller than .
Learning rate (Concept)


Because we need to minimize the error E, which is a function of the weights. Therefore, we compute the gradient of E with respect to the weights to find the best downhill direction at the current position of the weights in the weight space.
In the above diagram, the gradient (slope) at is negative. If is positive, the weight will increase after the update and the error E will reduce, which is what we need.


The learning rate should be small so that the change in the weights will not be very large in successive iterations. The key point is that we want to have small change in weights for each iteration so that eventually, we will reach the bottom of a valley. If the learning rate is very large, the change in weights will be so large that the error E may increase from iteration to iteration. This is similar to jumping from one side of the hill to the other side but never be able to reach the bottom.

No. It is a weakness of BP. BP is based on gradient descent. All gradient descent algorithm cannot find the global minimum (unless E(w) is quadratic in w). But in many real-world applications, it is not necessary to find the global minimum for the networks to be useful.
Activations
Softmax (Concept)

The advantage of softmax is that the sum over all outputs is equal to 1, which fits nicely to the requirement of posterior probabilities. That is, we may consider the k-th output produces the posterior probability of Class k given an input vector x.
The softmax function enables a network to output posterior probabilities of classes. Is this true?
True
Cross-entropy (Concept)

The MSE gives equal emphasis on all of the K outputs for a K-class problem. This means that the MSE () will be dominated by the errors for which , because among the K outputs, only one of them has target . On the other hand, the cross-entropy error emphasizes on the output for which . In fact, it aims to make the network to produce when and ignores all the other outputs for which . This is closer to the classification objective because to make a classification decision, we look for the largest output regardless of how large its rival is.
DNN for binary classification problems can use both categorical cross-entropy and binary cross-entropy as the loss function, whereas DNN for multi-class classification problems can only use categorical cross-entropy as the loss function. Is this true?
True
Regularization
Why do we need ?
So far, we consider the weight vectors 's live on a high-dimensional space without any restriction on the solution space.
This means that there could be infinite possibility for the optimal . We may impose some constraints on the learning algorithm to reduce the solution space. In this way, we can have higher chance to reach the optimal .
Purpose the ways of regularization techniques.
- L2-Norm (Weight Decay)
- Method: Adding a penality term (or known as ) to the weight update, thus to prevents a large network from getting overly complex but powerful enough to solve the problem. The idea is to shift the weight close to 0.
- L1-Norm (Sparsity Constraint)
- Method: Adding a penality term to the weight update, thus causes many of the weights become 0 (sparsity), making the network smaller.
- Weight decay (L2 norm) is preferred unless we want to compress our model.
- Dropout
- At every training iteration, we select some nodes (except the output nodes) with probability and remove them from the network.
- So, each iteration (mini-batch) has a different set of nodes.
- After training, all nodes will be used but the weights are rescaled by the keep probability .
- The idea is to obtain a large number of different network architecture from a single network by randomly dropping out nodes during training.
- Method: For every node, sample from a Bernoulli distribution. If it is 1, remove the node. If it is 0, keep the node.
- Data Augmentation
- We may generate more data from the existing training data.
- For image, we applying rotation, flipping, scaling, shifting, etc. to the training image
- For speech, we add noise at different SNR, different types of noise, and reverberation effect.
- If we only have feature vectors (no raw data such as images or waveform), we may use Generative Adversarial Networks to generate the augmented data.
L2-Norm Regularization (Math Derivation + Concept)

The L2 norm can be written as
where . If we take the derivative of the L2-norm, we obtain
Therefore, applying gradient descent on leads to
If is positively big, the last term of this update equation will make it smaller. On the other hand, if is negatively big, the last term of this update equation will make it less negatively big. The idea is to shift the weight close to 0.
Dropout (Concept)

where and are the output of the two hidden nodes and is the target activation at the output node, and is a nonlinear function. We emphasize that is the target activation so that achieves our desired goal (regression or classification). If the two hidden nodes are independently removed from the network, we have three possible actual activations at the output:
Because we could have either the upper branch or the lower branch of the network retaining during training but we want and , the SGD will make and bigger than necessary during inference where all nodes are kept. Therefore, during influence, we need to scale the weights by the keep probability . For the implementation that enforces at least one node to be dropped, the scaling will be exact.

In Dropout, the training task is solved by a large number of networks event though we define one network only. Is this true?
True. Dropout is implemented by randomly selecting nodes to be dropped-out with a given probability each weight update cycle. Therefore, in each weight update cycle there will be a different model.
Problems of Gradient-Based Methods
Vanishing Gradients (Concept)
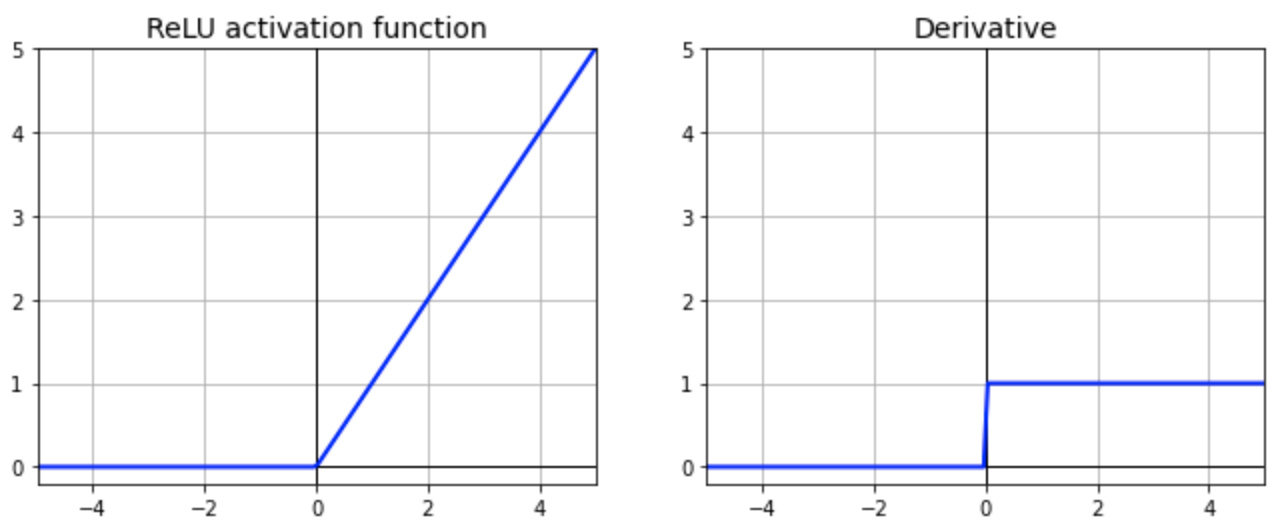
Explain why ReLU helps alleviate Vanishing Gradients.
In theory, the ReLU activation function could help mitigating the gradient vanishing problem. The derivative of the ReLU activation function is either 0 or 1. Since the gradient update of any layer make use of backpropagation technique, the number is multiplied by 1 or 0. Thus the gradient will either be 0 or keeping its weight.

It is because we have one extra term to reduce the chance of having small gradient, as the error gradient can be directly passed to lower layers.
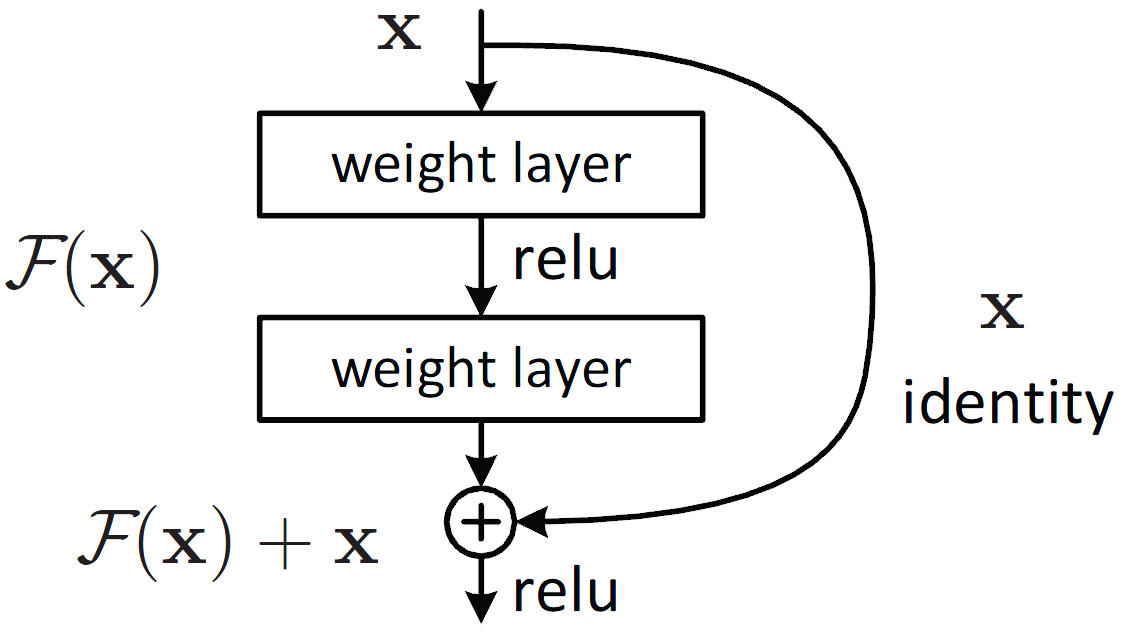
Besides ReLU and ResNet, Propose 3 more solutions to alleviate Vanishing Gradients.
Xavier initialization
If weights in a DNN are too small to begin with, the signal strength shrinks during forward propagation. If the weights are too large, the signal strength will drive the network to saturation (going too small or too large). Xavier initialization is to ensure that the weights are just right to start with.
Method: Randomly initialize weights at layer with zero means and variance depending on the no. of neurons at Layer and Layer :
Batch norm
The idea is to bring the input to the activation function closer to 0 so that the gradient becomes non-zero.
Method: Normalizing the activation across the batch to have 0 mean and unit variance:
- // mini-batch mean
- // mini-batch variance
- // normalize
During inference, we use the population statistics to perform the normalization:
is the mean activation of a node for all batches is the activation variance of a node for all batches
Layer norm
- For RNNs, it is difficult to apply batch normalization. It is because the mini batches in RNN will have different input sequence size, it cannot give a fixed mean to favor batch normalization.
- Layer norm is to apply normalization across the activation in a layer

Exploding Gradient (Concept)
Explain why Exploding Gradient happens.
When the initial weights generate some large loss, the gradients can accumulate during an update and result in very large gradients. The large gradients result in large updates to the network weights and leads to an unstable network. The parameters can sometimes become so large that they overflow and result in NaN values.
Another situation is when the weight vectors hit a cliff of the loss surface.
- The solution for this situation is to clip the gradient.
clip_grad_nor
Almost no data per class (Concept)
Gradient-based methods require many examples per class and many iterations of network updates for the network to converge. With only a few examples per class, the network simply does no converge or will be severely overfitted. Propose a solution to solve this problem.
- Transfer Learning
Reference
Batch Normalization and ReLU for solving Vanishing Gradients


