Prerequisite Knowledge
Domain Knowledge Terminologies
- Protein
- a combination of 20 types of amino acids
- Peptide
- a short sequence of amino acids
- Fold
- refers to the specific three-dimensional arrangement (shape and surface characteristics) of a polypeptide chain. Crucial for the protein’s function.
- Pathogens
- microorganisms that can cause disease
- Types of Pathogens: Bacteria, Viruses, Fungi, Parasites…
- Antigens
- Any substance that causes the body to make an immune response against that substance.
- can be used as markers in laboratory tests to identify those tissues or cells.
- Types of Antigens: toxins, chemicals, bacteria, viruses, or other substances that come from outside the body.
- Body tissues and cells, including cancer cells, also have antigens on them that can cause an immune response.
- T-Cell
- A type of immune cell that’s part of the body’s adaptive immune system, meaning it can learn to recognize and remember specific pathogens.
- Kill cells that have been infected or mutated that may cause harm (e.g. cancer)
- T-Cell Receptor (TCR)
- A molecule found on the surface of T-cells (A group of proteins found on T cells)
- T-cell receptors bind to certain antigens (proteins) found on abnormal cells, cancer cells, cells from other organisms, and cells infected with a virus or another microorganism.
- This interaction causes the T cells to attack these cells and helps the body fight infection, cancer, or other diseases.
Think of T-cells as security guards in a high-security facility (your body).
The T-cell receptor is like a specialized scanner each guard carries.
Just as a scanner helps identify unauthorized personnel or objects, the T-cell receptor helps the T-cell recognize and respond to invaders.
TCR-dWAE
Paper: Disentangled Wasserstein Autoencoder for T-Cell Receptor Engineering
Some parts of a protein are crucial for its function (like where it binds to other molecules), while other parts are important for maintaining its overall shape. But each part cannot work on its own without another part.
- Finding and changing the important functional parts is key for designing new proteins
- Need to keep the overall structure while only functionally relevant part are changed for the efficiency
- Challenging task because requires domain knowledge and limited to specific scenarios
- Proposed Wasserstein Autoencoder (WAE) + Auxiliary Classifier
- to separate function and structure
- Disentangled representation learning
- similar to the content-style separation in computer vision and NLP problem
- protein sequence separately embedded into a “functional” embedding and “structural” embedding
- Tested on T-cell Receptors because its a well-studied structure-function case
- proposed method can alter the functions of TCR without changing the structural backbone
- First work to utilize disentangled representations for TCR Engineering
In practice, it is difficult to predict the real “structure” in the sense of protein 3D structure for CDR3beta region because it is a very flexible loop, and high-quality structure is scarce. Additionally, it cannot be predicted from the CDR3beta sequence alone, ignoring the rest of the TCR. Thus, we can only rely on the available sequential information of known CDR3beta’s to determine whether generated ones are valid, or whether they preserve the structural backbone, based on the intuition that the structure is defined by the sequence. Thus, if certain pivotal residues and motifs (which we try to make the “structural embedding” learn) are similar between two sequences (e.g. generated and known), they should have similar structures.
Problem Definition
Given A TCR sequence and a peptide that it could not bind to:
- Introduce a minimal number of mutations so that it can bind
- TCR needs to remain valid, with no major changes in the structural
TCRs that bind to the same peptide should have similar function patterns
- Focused on CDR3β region of TCRs (the most active region for TCR binding)
The CDR3 (Complementarity-Determining Region 3) is a unique segment of the T-cell receptor. It plays a crucial role in recognizing and responding to antigens presented by antigen-presenting cells

(A) Top: The TCR recognizes antigenic peptides provided by the major histocompatibility complex (MHC) with high specificity; bottom: the 3D structure of the TCR-peptide-MHC binding interface (PDB: 5HHO); the CDRs are highlighted.
Method
| Notation |
Meaning |
| Θf |
functional encoder |
| Θs |
structural encoder |
| Γ |
decoder |
| Ψ |
auxiliary functional classifier |
| {x,u,y} |
a data point with TCR x, peptide u and binding label y |
| zf |
functional embedding |
| zs |
structural embedding |
| z |
concatenation of {zf,zs} |
| x′ |
reconstructed/generated sequence from the decoder |
| x(i) |
the probability distribution over amino acids at the i-th position in x |
| concat(x1,…,xn) |
concatenation of vectors {x1,…,xn} |

The disentangled autoencoder framework (WAE), where the input x, i.e., the CDR3β, is embedded into a functional embedding zf (orange bar) and structural embedding zs (green bar).
Architectures
Input sequences are padded to the same length (25). The peptide u is presented as the average BLOSUM50 score for all its amino acids
-
Embedding layer
- tranform the one-hot encoded sequence x into continuous-valued vectors of 128 dim
-
Trasnformer encoders as functional encoder Θf and structural encoder Θs
- 1 layer transformer with 8 attention heads and an intermediate size of 128
- 2-layer MLP with a 128-dim hidden layer built on top of the transformer to transform the output to the dimensions of zf and zs respectively
-
LSTM decoder as decoder Γ
-
MLP as auxiliary functional classifier Ψ
- 2-layer MLP with 32-dim hidden layer
WAE is trained deterministically, avoiding several practical challenges of VAE in general, especially on sequences.
- End-to-End training
- Trained with Adam Optim for 200 epochs, lr = 1e-4
Loss Functions
L=Lrecon+β1Lc+β2Lwass
-
Binding Prediction Loss Lc
- Binary Cross Entropy (BCE)
-
Reconstruction Loss Lrecon
- Position-wise Binary Cross Entropy (BCE) across all positions of the sequence
- β1=1.0 in the paper
-
Wasserstein autoencoder regularization Lwass
-
by minimizing the MMD (maximum mean discrepancy) between the distribution of the embeddings and an isotropic multivariate Gaussian prior, so that zf and zs are independent.
- embeddings Z∼QZ where z=concat(zf,zs)
- isotropic multivariate Gaussian prior Z0∼PZ where PZ=N(0,Id)
-
MMD(PZ,QZ)=[n/2]1i∑[n/2]h((z2i−1,z~2i−1),(z2i,z~2i))
- where h((z2i−1,z~2i−1),(z2i,z~2i)=k(zi,zj)+k(z~i,z~j)−k(zi,z~j)−k(zj,z~i) and k is the RBF kernel function with σ=1.
-
β2=0.1 in the paper
Inference

Method for sequence engineering with input x. structural embedding zs of the template sequence and a modified z′f functional embedding, are fed to the decoder to generate engineered TCRs x′
Disentanglement Guarantee
For some generative models, such as diffusion models, there is no “explicit” latent space. Methods like VAE and WAE “explicitly” model the distribution of the latent space, so we could directly enforce disentanglement on that latent space.
The measurement of disentanglement of the embeddings Zf and Zs given the variable U (peptide).
D(Zf,Zs;X∣U)=VI(Zs;X∣U)+VI(Zf;X∣U)−VI(Zf;Zs∣U)
where VI is the variation of information, measuring of independence between two random variables.
We want to minimize D(Zf,Zs;X∣U)
the condition U is omitted for the sake of simplicity.
VI(X;Y∣U)=H(X∣U)+H(Y∣U)−2I(X;Y∣U)VI(X;Y)=H(X)+H(Y)−2I(X;Y)
- H is the Entropy
- I is the Mutual Information
https://en.wikipedia.org/wiki/Mutual_information
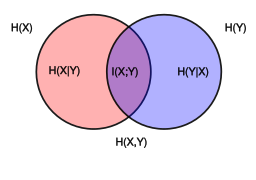
This measurement reaches 0 when Zf and Zsare totally independent, i.e. disentangled
Sub VI(X;Y)=H(X)+H(Y)−2I(X;Y) into VI(Zs;X)+VI(Zf;X)−VI(Zf;Zs), we get:
VI(Zs;X)+VI(Zf;X)−VI(Zf;Zs)=H(Zs)+H(X)−2I(Zs;X)+H(Zf)+H(X)−2I(Zf;X)−H(Zf)−H(Zs)+2I(Zf;Zs)
Cancelling out the terms:
VI(Zs;X)+VI(Zf;X)−VI(Zf;Zs)=2H(X)+2[I(Zf;Zs)−I(Zs;X)−I(Zf;X)]
https://en.wikipedia.org/wiki/Data_processing_inequality
Data Processing Inequality
As zf→x→y forms a markov chain,
Using the mutual information, this can be written as :
I(x;zf)≥I(y;zf)
Therefore we have the upper bound of the disentanglement objective (right hand side)
I(Zf;Zs)−I(Zs;X)−I(Zf;X)≤I(Zf;Zs)−I(Zs;X)−I(Zf;Y)
Then we can minimize the whole upper bound term I(Zf;Zs)−I(Zs;X)−I(Zf;Y).
Maximizing I(Zs;X)
Similar to Disentangled Recurrent Wasserstein Autoencoder
According to the Theorem, Given the encoder Qθ(Z∣X), decoder Pγ(X∣Z), prior P(Z), and the data distribution PD
DKL(Q(Z)∥P(Z))=EpD[DKL(Qθ(Z∣X)∥P(Z))]−I(X;Z)
where Q(Z) is the marginal distribution of the encoder when X∼PD and Z∼Qθ(Z∣X).
Proof:
Joint Generative Distribution:
p(x,z)=pγ(x∣z)p(z)
Joint Inference Distribution:
q(x,z)=qθ(z∣x)pD(x)
Now find I(X;Z):
I(X;Z)=Eq(x,z)logpD(x)q(z)q(x,z)
Since q(x,z)=qθ(z∣x)pD(x), expend the term and cancel out pD(x)
Eq(x,z)logpD(x)q(z)q(x,z)=Eq(x,z)logpD(x)q(z)qθ(z∣x)pD(x)=Eq(x,z)logq(z)qθ(z∣x)
Since E[XY]=E[X]E[Y] for independent variables X,Y, Using the formula we can decompose the joint expectation into the product of expectations Eq(x,z)=EpD(x)Eqθ(z∣x).
For Conditional expectations, E[X∣A]=∑xxP(X=x∣A), so Eqθ(z∣x)=∑zqθ(z∣x)
Eq(x,z)logq(z)qθ(z∣x)=EpD(x)Eqθ(z∣x)logq(z)qθ(z∣x)=EpD(x)z∑qθ(z∣x)logq(z)qθ(z∣x)
We need to rewrite this in a way that reflects both the joint distribution and marginal components. Rewrite the expectation to explicitly show pD(x) so once inside the summation and once inside the logarithm.
EpD(x)z∑qθ(z∣x)logq(z)qθ(z∣x)=EpDz∑qθ(z∣x)logpD(x)q(z)qθ(z∣x)pD(x)
EpDz∑qθ(z∣x)logpD(x)q(z)qθ(z∣x)pD(x)=EpDz∑pD(x)qθ(z∣x)logpD(x)q(z)qθ(z∣x)pD(x)
Then cancel out the term pD(x)
EpDz∑pD(x)qθ(z∣x)logpD(x)q(z)qθ(z∣x)pD(x)=EpDz∑pD(x)qθ(z∣x)logq(z)qθ(z∣x)
Since pD(x) is part of the expectation EpD, we can factor it out of the summation
EpDz∑pD(x)qθ(z∣x)logq(z)qθ(z∣x)=EpDz∑qθ(z∣x)logq(z)qθ(z∣x)
Using the logarithmic property logba=log(ca×bc)=log(ca/cb)=logca−logcb:
EpDz∑qθ(z∣x)logq(z)qθ(z∣x)=EpDz∑qθ(z∣x)logp(z)qθ(z∣x)−EpDz∑qθ(z∣x)logp(z)q(z)
=EpDz∑qθ(z∣x)logp(z)qθ(z∣x)−z∑q(z)logp(z)q(z)
As the definition of KL divergence equation DKL(P∣∣Q)=∑iP(i)logQ(i)P(i)
=EpD[DKL(Qθ(Z∣X)∥P(Z))]−DKL(Q(Z)∥P(Z))
This final form is often used in variational inference, where it measures how well the conditional distribution qθ(z∣x) fits the prior p(z) on average, and compares this to the overall fit of the marginal q(z) with respect to the prior.
Shortened version (From the paper):
I(X;Z)=Eq(x,z)logpD(x)q(z)q(x,z)=EpDz∑pD(x)qθ(z∣x)logpD(x)q(z)qθ(z∣x)pD(x)=EpDz∑qθ(z∣x)logq(z)qθ(z∣x)=EpDz∑qθ(z∣x)logp(z)qθ(z∣x)−EpDz∑qθ(z∣x)logp(z)q(z)=EpDz∑qθ(z∣x)logp(z)qθ(z∣x)−z∑q(z)logp(z)q(z)=EpD[DKL(Qθ(Z∣X)∥P(Z))]−DKL(Q(Z)∥P(Z))
Therefore by minimizing the KL divergence between the marginal Q(Z) and the prior P(Z), the mutual information I(Z;X) is maximized.
Revisit KL Divergence:
- KL Divergence measures how different two probability distributions are from each other.
- Asymmetric (meaning the result changes if the distributions are switched.), KL(Q||P) does not equal to KL(P||Q).
- Log transformation is used to address biases in averaging large numbers.
This part corresponds to the training of Autoencoder. In practice, MMD (maximum mean discrepancy) between the distribution of the embeddings
Maximizing I(Zs;Y)
I(Zs;Y) has a lower bound
I(Y;Zf)=H(Y)−H(Y∣Zf)I(Y;Zf)≥H(Y)+Ep(Y,Zf)logqΨ(Y∣Zf)
Therefore maximizing the performance of classifier ψ would maximize I(Y;Zf)
Minimizing I(Zf;Zs)
By minimizing the Wasserstein loss between the distribution of the embeddings and an isotropic multivariate Gaussian prior, so that zf and zs are independent.
- Forces the embedding space Z to approach an isotropic multivariate Gaussian prior Pz=N(0,Id) where all the dimensions are independent
Minimizing the mutual information between the two parts of the embedding Zf and Zs is achieved by ensuring that the dimensions of Z are independent.
Data Preparation
TCR-peptide interaction data from:
TCR-VALID
Paper: Designing meaningful continuous representations of T cell receptor sequences with deep generative models






