
Advanced Techniques of Diffusion Models
Advanced Techniques: Accelerated Sampling, Conditional Generation
Advanced Techniques of Diffusion Models: Accelerated Sampling, Conditional Generation
How to accelerate the sampling process
What makes a good generative model?
- Fast sampling from the generative model
- Model coverage/ diversity (generative model capture most of the major modes of the data distribution)
- High quality / high fidelity samples
| GANs | VAEs, Normaling Flows | Diffusion Models | |
|---|---|---|---|
| Fast Sampling | ✅ | ✅ | ❌ |
| Mode coverage/ diversity | ❌ | ✅ | ✅ |
| High quality samples | ✅ | ❌ | ✅ |
Accelerating Diffusion Models
Naive accelerate methods, such as reducing diffusion timesteps in training or sampling every k timestep in inference, lead to immediate worse performance.
Advanced forward process
- Does the noise schedule have to be predefined?
- Does the forward process of DDPM has to be a Markovian process?
- Is there any faster mixing diffusion process?
Covering: VDM, DDIM, Critically-damped Langevin diffusion
Variational Diffusion Models
Variational Diffusion Models: https://arxiv.org/abs/2107.00630
Learnable diffusion process => Include Learnable Parameters in the encoder
- Given the forward process
- Directly parametrize the variance through a learned function :
- is a monotonic MLP
- Strictly positive weights and monotonic activations (e.g. sigmoid)
New parametrization of training objectives
We call that we learned that the diffusion models can be interpreted from the perspective of SDE (Stochastic Differential Equation), and we learned the connection between diffusion models and denoising score matching. This implies that the diffusion models can also be defined in the continuous-time setting.
- Optimizing variational upper bound of diffusion models can be simplified to the following training objective:
- Letting leads to variation upper bound in continuous-time
- When , we have infinity amount of diffusion steps which corresponds to a continuous time setting and then the variantion upper bound can be derived
- It is shown to be only related to the signal-to-noise ration at endpoints, invarient to the noise schedule in-between. It means we only need to optimize the SNR at the beginning and the end of the forward process
- The continuous-time noise schedule can be learned to minimize the variance of the training objective for faster training.
SOTA likelihood estimation (significant improvements in log-likelihoods)
- Appending Fourier features to the input of U-Net
- Hypothesis: To get good likelihoods, the model need to modeling all the bits (details in the input signal, both perceptual and inperceptual). But neural nets are usually bad at modeling small changes to inputs.
Denoising Diffusion Implicit Models (DDIM)
Denoising Diffusion Implicit Models: https://arxiv.org/abs/2010.02502
Non-Markovian Diffusion Process
- Define a family of non-Markovian diffusion processes and corresponding reverse processes.
- The process is designed such that the model can be optimized by the same surrogate objective as the original diffusion model.
- Recall the objective of the original diffusion model:
- Therefore can take a pretrained diffusion model but with more choices of sampling procedure.
To Define the non-Markovian forward process
Recall the Objective of diffusion models:
KL divergence in the variational upper bound can be written as
- is the posterior distribution
- is the denoising distribution
- Since both distributions are Gaussian distributions with the same variance , this can be written as the L2 distance between the mean of the 2 distributions and times a constant
https://vinesmsuic.github.io/paper-ddpm/#Objective-function-of-Diffusion
Recall the two mean functions , have been parametrized by simple linear combination of
Then we can rewrite to
where
If we assume loss weightings can be arbitrary values (the surrogate objective simply set as 1), the above formulation holds as long as
- follows a normal distribution
- (to Make sure will equals to )
Then we have two assumptions:
- Forward process: , which the mean of the gaussian distribution is a linear combination of such that
- Reverse process: , which the mean of the gaussian distribution is also a linear combination of and the predicted noise such that
Since
We can rewrite the Forward process formula and Reverse process formula
- (assume )
Which means we need not to specify to be a Markovian process.

- Now for each it depends on both and the
- For our linear combination , we need to choose the such that
Therefor with the rules we define a family of forward processes that meets the above requirement:
The corresponding reverse process is
DDIM Sampler - Deterministic generative process
In
If we specify (for all the timesteps), this list to the DDIM sampler which is a deterministic generative process, with randomness from only .
ODE interpretation - Deterministic generative process
Generative Probability Flow ODE (deterministic):
DDIM Sampler can be considered as an integration rule of the following ODE:
where
-
- Simply appling a scaling factor
-
- Sqaure root of the inverse SNR
If is optimal, we have an optimal model
With the optimal model, the ODE is equivalent to a probability flow ODE of a “variance-exploding” SDE:
where
Although with the optimal model, the ODE is equivalent to a probability flow ODE of a “variance-exploding” SDE, the Sampling procedure can be different from standard Euler’s method: wrt. vs wrt
In practice, we the ODE works better than the SDE here because it depends less on the value of . it depends directly on the SNR of the current timesteps
DDIM Sampler - Faster and low curvature
- Karras et al. argues that the ODE of DDIM is favored, as the tangent of the solution trajectory always point towards the denoiser output
- Leads to largely linear solution trajectories with low curvature
- Low curvature means less truncation errors accumulated over the trajectories
Critically-damped Langevin diffusion
Score-Based Generative Modeling with Critically-Damped Langevin Diffusion: https://arxiv.org/abs/2112.07068
Find a “fast mixing diffusion process”
Recall the regular forward diffusion process as SDE
It is a special case of (overdamped) Langevin dynamics
if we assume
“Momentum-based” diffusion - introduce a velocity variable and run diffusion in extended space
With this equation we can design more efficient forward process in term
- Introduce an auxiliary variable velocity
- the diffusion process is defined in the joint space of the velocity and the input
- during forward process, noise is only added in the velocity space
- while image (input) space is only erupt by the coupling between the data and the velocity

Result:
- The process in the V space is still zig-zag
- But the process in the image (input) space are more much smoother
- Faster mixing and faster traverse of joint space
- Smooth and efficient forward process
Analogous to Hamiltonian component / momentum in momentum-based optimizers
Advance Reverse Process
- we assume the denoising distributions are always Gaussian distributions. If we want to use less diffusion time steps, is this normal approximation of the reverse process still true of accurate?
- No, the assumption only holds only when the noises added between the adjacent steps are small.

- We need complicated functional approximators if we want to have less diffusion steps
Covering: Denoising Diffusion GANs, Diffusion energy-based models
Denoising Diffusion GANs
Tackling the Generative Learning Trilemma with Denoising Diffusion GANs: https://nvlabs.github.io/denoising-diffusion-gan/
Approximating reverse process by conditional GANs
-
Since the conditional GAN only need to model the conditional distribution of , this is a simple problem for both generator and discriminator to learn
- Stronger mode coverage and Better training stability
Diffusion energy-based models
Learning Energy-Based Models by Diffusion Recovery Likelihood: https://arxiv.org/abs/2012.08125
Approximating reverse process by conditional energy-based models
Recall an energy-based model (EBM) is in the form
where
- is a partition function that Analytically intractable
- is an energy function
Optimizing energy-based models requires MCMC sampling from the current model
So if we want to parametrize the denoising distribution by conditional energy based model, we need to assume at each diffusion timestep marginally the data follows the EBM in the standard formulation .
Let (data at a higher noise level)
So we can derive the conditional energy-based models by Bayes’ rule:
where
- The term helps to localize the highly multimodal energy landscape, thus getting a more unimodal landscape and with the modal, mode focus around the higher noise level signal
To learn the model we simply maximize the conditional log-likelihoods:
After training we just get samples by progressive sampling from EBMs from high-noise levels to low-noise levels.
Compared to a single EBM:
- Sampling is more friendly and easier to converge
- Training is more efficient
- Well-formed energy potential
Compared to diffusion models:
- Much less diffusion steps
Model distillation
- Can we do model distillation for fast sampling
Cover: Progressive distillation
Progressive Distillation
Progressive Distillation for Fast Sampling of Diffusion Models: https://arxiv.org/abs/2202.00512
- Distill a deterministic DDPM sampler to the same model architecture
- At each stage, a “student” model is learned to distill two adjacent sampling steps of the “teacher” model to one sampling step
- At next stage, the “student” model from previous stage become the new “teacher” model and repeat
Hybrid models
- Can we lift the diffusion model to a latent space that is faster to diffuse?
Cove: LDM
Latent-space diffusion models (LDM)
Score-based Generative Modeling in Latent Space: https://nvlabs.github.io/LSGM/
High-Resolution Image Synthesis with Latent Diffusion Models: https://arxiv.org/abs/2112.10752
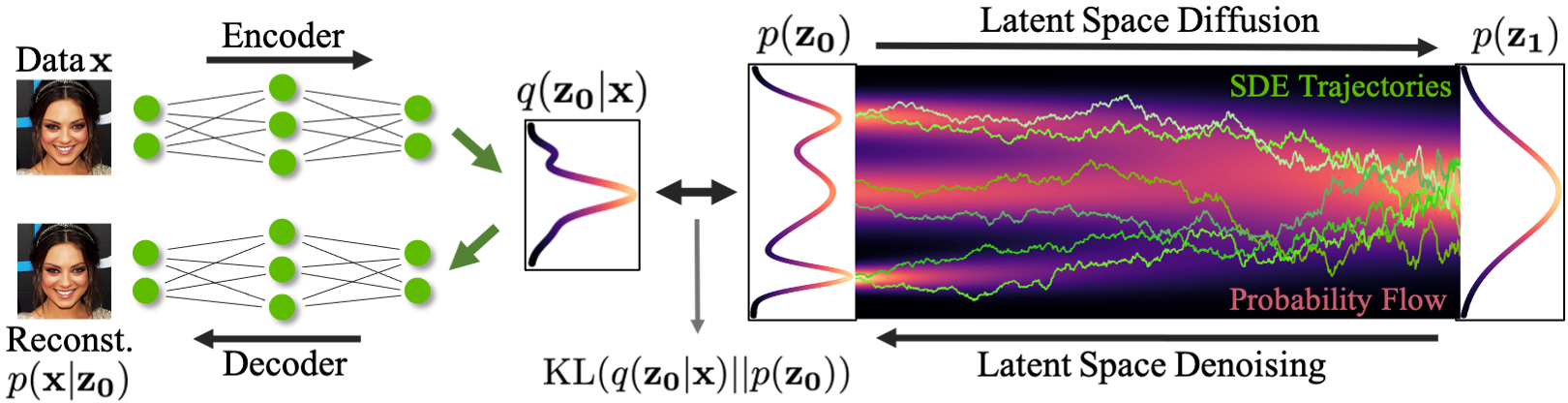
^ Variational Autoencoder (VAE) + Score-based Prior
Main idea: Lift the diffusion models to a latent space which is more friendly to the diffusion process
- Encoder maps the input data to an embedding space
- Denoising diffusion models are applied in the latent space
Advantages:
-
The distribution of latent embeddings close to Normal distribution
- Simpler denoising and faster synthesis
-
Augmented latent space
- More expressivity
-
Tailored Autoencoders
- More expressivity, Application to any data type (e.g. graphs, text, 3d data etc.)
Training objective of LDM: score-matching for cross-entropy
where
- It is optimized by minimizing the variational upper bound negative log likelihood
- the reconstruction term and negative encoder entropy are similar to the training objective of VAE
- the cross entropy term corresponds to the training objective of Diffusion models
Then the objective can be written as
where
- is the time sampling
- is the forward diffusion
- is the diffusion kernel
- is the trainable score function
- is some constant
Conditional Diffusion Models
How to do high-resolution (conditional) generation?
- Reverse process is changed
Reverse Process (taking conditional input ):
Incorparate conditions into U-Net of the diffusion model
- Scalar conditioning: encode scalar as a vector embedding, simple spatial addition or adaptive group normalization layers
- Image conditioning: channel-wise concatenation of the conditional image
- Text conditioning:
- single vector embedding: spatial addition or adaptive group norm
- a sequence of vector embeddings: cross-attention
Classifier Guidance
Diffusion models beat GANs on image synthesis: https://arxiv.org/abs/2105.05233
Using the gradient of a trained classifier as guidance
Main idea:
-
For class-conditional modeling of , train an extra classifier
- Mix its gradient with the diffusion/score model during sampling
-
Sample with a modified score:
-
Approximate samples from the distribution
Classifier-Free Guidance
Classifier-Free Diffusion Guidance: https://arxiv.org/abs/2207.12598
Get guidance by Bayes’ rule on conditional diffusion models
Main idea:
- Instead of training an additional classifier, get an “implicit classifier” by jointly training a conditional and unconditional diffusion model
-
- Where is the conditional diffusion model, is the unconditional diffusion model
-
- In practice, and by randomly dropping the condition of the diffusion model at certain chance
- The modified score with this implicit classifier included is:
-
Trade-off for sample quality and sample diversity
- Large guidance weight usually leads to better individual sample quality but less sample diversity
Cascaded generation
Cascaded Diffusion Models for High Fidelity Image Generation: https://cascaded-diffusion.github.io
Main idea:
- Cascaded Diffusion Models (CDM) are pipelines of diffusion models that generate images of increasing resolution.
- CDMs yield high fidelity samples superior to BigGAN-deep and VQ-VAE-2 in terms of both FID score and classification accuracy score on class-conditional ImageNet generation. These results are achieved with pure generative models without any classifier.
- Introduce conditioning augmentation, data augmentation technique that find critical towards achieving high sample fidelity.
Noise conditioning augmentation: Reduce compounding error
Need robust super-resolution model:
- Training conditional on original low-res images from the dataset
- Inference on low-res images generated by the low-res model.
^If there are artifacts in the low-resolution sample will affact the sample quality due to mismatch conditions of two points
To alleviate this problem:
Noise conditioning augmentation
- During training, add varying amounts of Gaussian noise ( or blurring by Gaussian kernel) to the low-res images
- During inference, sweep over the optimal amount of noise added to the low-res images
- BSR-degradation process: applies JPEG compressions noise, camera sensor noise, different image interpolations for downscampling, Gaussian blue kernels and Gaussian noise in a random order to an image.





