
Overview of CNN - Architectures
CNN Architectures
Convolutional Networks are commonly made up of only three layer types: CONV, POOL and FC Layers.
General Layer Pattern
The most common form of a ConvNet architecture stacks a few CONV-RELU layers, follows them with POOL layers, and repeats this pattern until the image has been merged spatially to a small size. At some point, it is common to transition to fully-connected layers. The last fully-connected layer holds the output, such as the class scores.
General Layer Pattern:
Where indicates repetition, and the indicates an optional pooling layer.
- and usually
- and usually
Common Layer Patterns
Basic Pattern:
Single CONV layer between every POOL layer:
2 CONV layers stacked before every POOL layer:
multiple stacked CONV layers can develop more complex features of the input volume before the destructive pooling operation.
Layer Sizing Patterns
Rules of thumb for sizing the architecture
When setting the hyperparameters of the Layers, such as the size of layer, We need to follow some rules.
HyperParameter Matters
The Layer Accepts a volume of size . (Width x Height x Depth)
Hyperparameters:
- Number of Kernel Filters
- Spatial Extent of Kernel Filters
- The Stride
- The amount of Zero Padding
Input Layer
- The input layer (that contains the image) should be divisible by 2 many times (or divisible by at least 4).
- Best to be square images (speed up matrix calulcations)
- Common numbers : 32, 64, 96, 224, 384, 512
Examples :
- CIFAR-10 : 32x32 pixels coloured image
- STL-10 : 96x96 pixels coloured image
- ImageNet - 224x224 pixels coloured image
CONV Layers
- Small Filters (3x3 or at most 5x5) should be used
- Padding should be equal to if you want to keep the size of input
- Keeping the spatial sizes constant after CONV actually improves performance
Padding the input volume with zeros in such way that the conv layer does not alter the spatial dimensions of the input. That is, when , the output will preserve the original size of the input.
POOL Layers
- The most common setting is to use max-pooling with:
- 2x2 receptive fields
- Stride of 2 when inputs are large
This discards exactly 75% of the activations in an input volume (due to downsampling by 2 in both width and height).
-
Less common setting:
- 3x3 receptive fields
- Stride of 2 when inputs are large
-
It is very uncommon to see receptive field sizes for max pooling that are larger than 3 because the pooling is then too lossy and aggressive. This usually leads to worse performance.
Architectural Decisions

ILSVRC stands for (ImageNet Large Scale Visual Recognition Challenge)
- We rarely ever have to train a ConvNet from scratch or design one from scratch.
- Just use the current common architectures
In 90% or more of applications you should not have to worry about these. Instead of rolling your own architecture for a problem, you should look at whatever architecture currently works best on ImageNet, download a pretrained model and finetune it on your data.
Hyperparameter Decisions

ILSVRC stands for (ImageNet Large Scale Visual Recognition Challenge)
- “Look into papers, look what hyperparameters they use for the most part and you will see all papers use the same hyperparameters. They look very similar.” - Andrej Karpathy
The Architectures of Pre-Trained Model
Note the pre-trained model are usually complex and with many layers, therefore they took a very long time to train and we usually won’t train the model again with the exact same architecture.
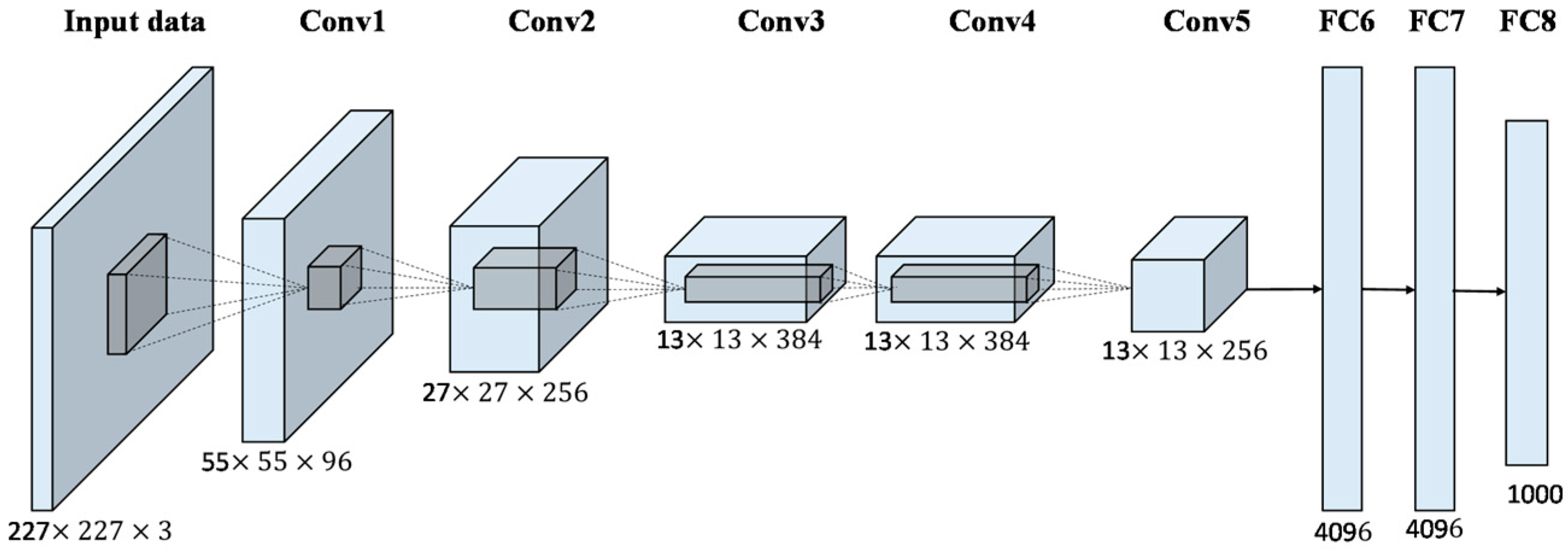
AlexNet
One of the simplest Architecture.
VGGNet
One of the simplest and best CNN Architecture is VGG Net. (VGG16: Configuration D)


GoogleNet

ResNet

Further Reading:
More Info About Different CNN Architectures
Transfer Learning
When come to practical situations, we will mostly use a pre-trained model.
“In practice, very few people train an entire Convolutional Network from scratch (with random initialization), because it is relatively rare to have a data set of sufficient size. Instead, it is common to pretrain a ConvNet on a very large dataset (e.g. ImageNet, which contains 1.2 million images with 1000 categories), and then use the ConvNet either as an initialization or a fixed feature extractor for the task of interest.”
The hard work of optimizing the parameters has already been done for you, now what you have to do is fine-tune the model by playing with the hyperparameters so in that sense, a pre-trained model is a life-saver.

Reference
DeepLizard - Machine Learning & Deep Learning Fundamentals
Deep Learning for Computer Vision (Andrej Karpathy, OpenAI)


