
Paper Review - Prompt-to-Prompt, Null-Text Inversion
Prompt to Prompt
Paper: Prompt-to-Prompt Image Editing with Cross Attention Control
Project Page: https://prompt-to-prompt.github.io/
Code: https://github.com/google/prompt-to-prompt/

Key takeaway:
- Prompt-to-Prompt uses a Attention map to create a local path, with fixing the seed and attention weights it become able to edit the object without altering the other objects/background.
- The Attention maps shown in the figure were the Averaged attention maps across multiple heads, and it does not guarantee a semantic segmentation
- So far the model only work well for generated image from the same model. For real-images edit, we need to invert the photo back to the latent space (inversion, which is the difficult part because this has not yet been fully addressed for text-guided diffusion models.)
Abstract
we propose to control the attention maps of the edited image by injecting the attention maps of the original image along the diffusion process.
- high-dimensional tensors that bind pixels and tokens extracted from the prompt text. We find that these maps contain rich semantic relations which critically affect the generated image.
Key foundings
Our key observation is that the structure and appearance of the generated image depend not only on the random seed, but also on the interaction between the pixels to the text embedding through the diffusion process. By modifying the pixel-to-text interaction that occurs in cross-attention layers, we provide Prompt-to-Prompt image editing capabilities. More specifically, injecting the cross- attention maps of the input image enables us to preserve the original composition and structure.

Method
To Align Image and Text, visual embedding (Conv layer) and textual embedding (Tokens) are fused using
Text-to-Image Cross Attention. It produce attention maps for each textual token.
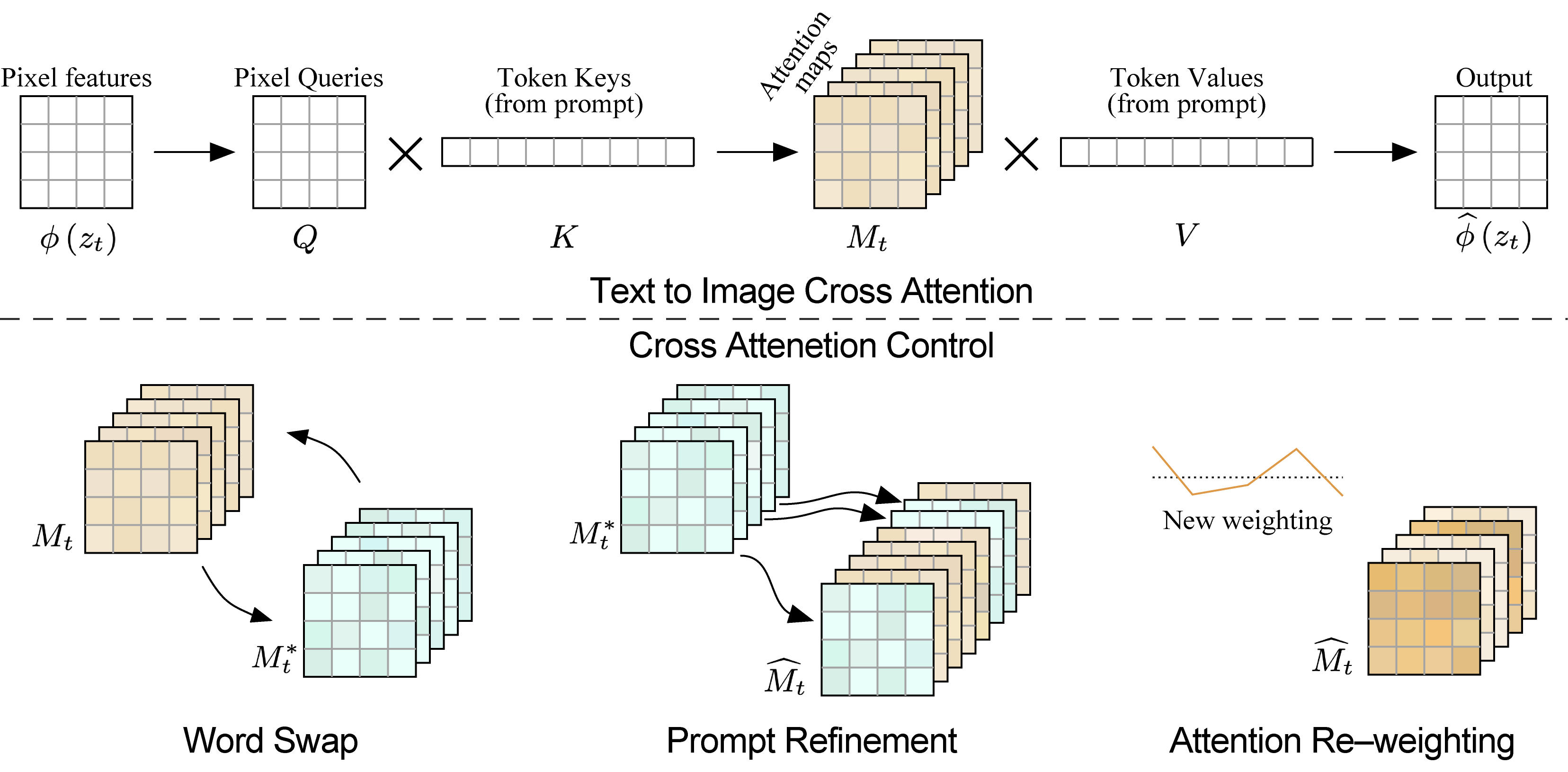
To enable image editing, we control the spatial layout and geometry of the generated image using the attention maps of a source image. When swapping a word in the prompt, we inject the source image maps , overriding the target maps . In the case of adding a refinement phrase, we inject only the maps that correspond to the unchanged part of the prompt. To amplify or attenuate the semantic effect of a word, we re-weight the corresponding attention map.
Limitations
DDIM-based inversion might result failure
Editing a real image requires finding an initial noise vector that produces the given input image when fed into the diffusion process.
current inversion process (DDIM-Inversion) results in a visible distortion over some of the test images

Inversion requires the user to come up with a suitable prompt which could be challenging for complicated compositions.
Possible Solution to both issues : Null Text Inversion
Attention maps are of low resolution
The cross-attention is placed in the network’s bottleneck
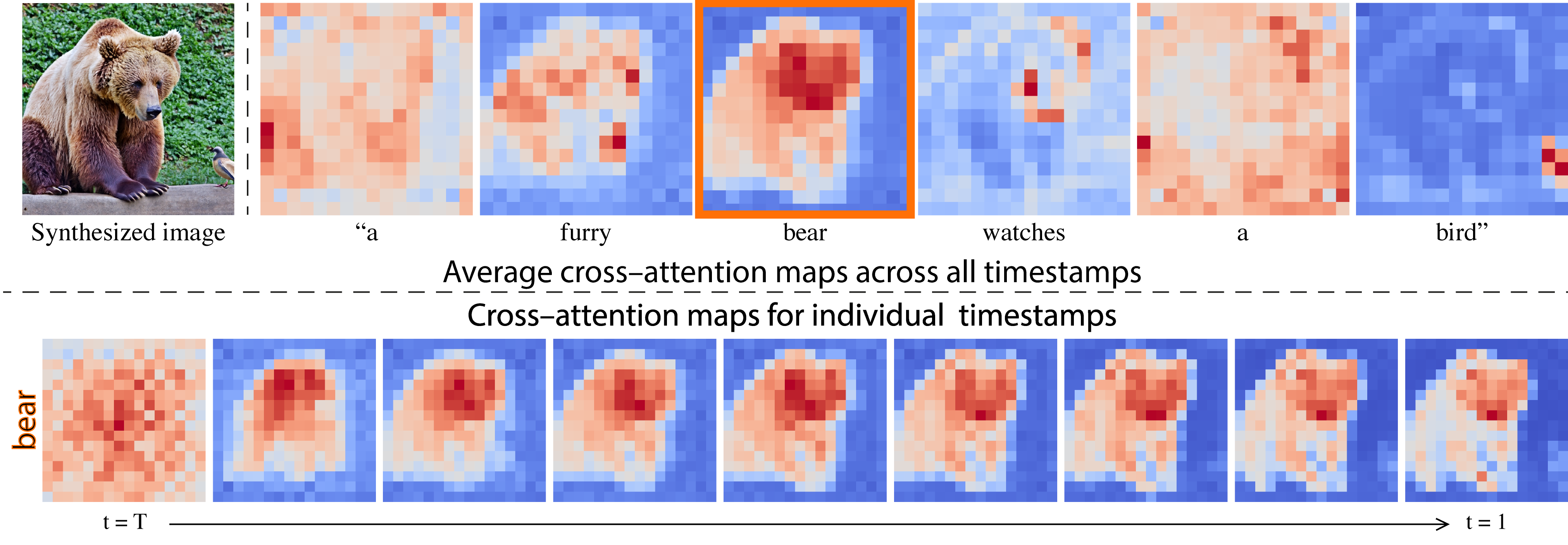
- bounds the ability to perform more precise editing
Possible Solution: incorporating cross-attention also in higher-resolution layers
- The paper authors leave this for future work as it requires analyzing the training which is out of our scope.
Null Text Inversion
Real Image Editing with Prompt2Prompt
Paper: https://arxiv.org/abs/2211.09794
Project Page: https://null-text-inversion.github.io/
Code: https://github.com/google/prompt-to-prompt/

Abstract
we introduce an accurate inversion technique and thus facilitate an intuitive text-based modification of the image.
Our proposed inversion consists of two novel key components:
- (i) Pivotal inversion for diffusion models. While current methods aim at mapping random noise samples to a single input image, we use a single pivotal noise vector for each timestamp and optimize around it.
- (ii) null-text optimization, where we only modify the unconditional textual embedding that is used for classifier-free guidance, rather than the input text embedding. This allows for keeping both the model weights and the conditional embedding intact and hence enables applying prompt-based editing while avoiding the cumbersome tuning of the model’s weights.
Method
- Inspired by GAN inversion method and perform a more “local” optimization, ideally using only a single noise vector. aim to perform our optimization around a pivotal noise vector which is a good approximation and thus allows a more efficient inversion.
We first apply an initial DDIM inversion on the input image which estimates a diffusion trajectory (top trajectory). Starting the diffusion process from the last latent code results in unsatisfying reconstruction (bottom trajectory) as the intermediate codes become farther away from the original trajectory. We use the initial trajectory as a pivot for our optimization which brings the diffusion backward trajectory closer to the original image.
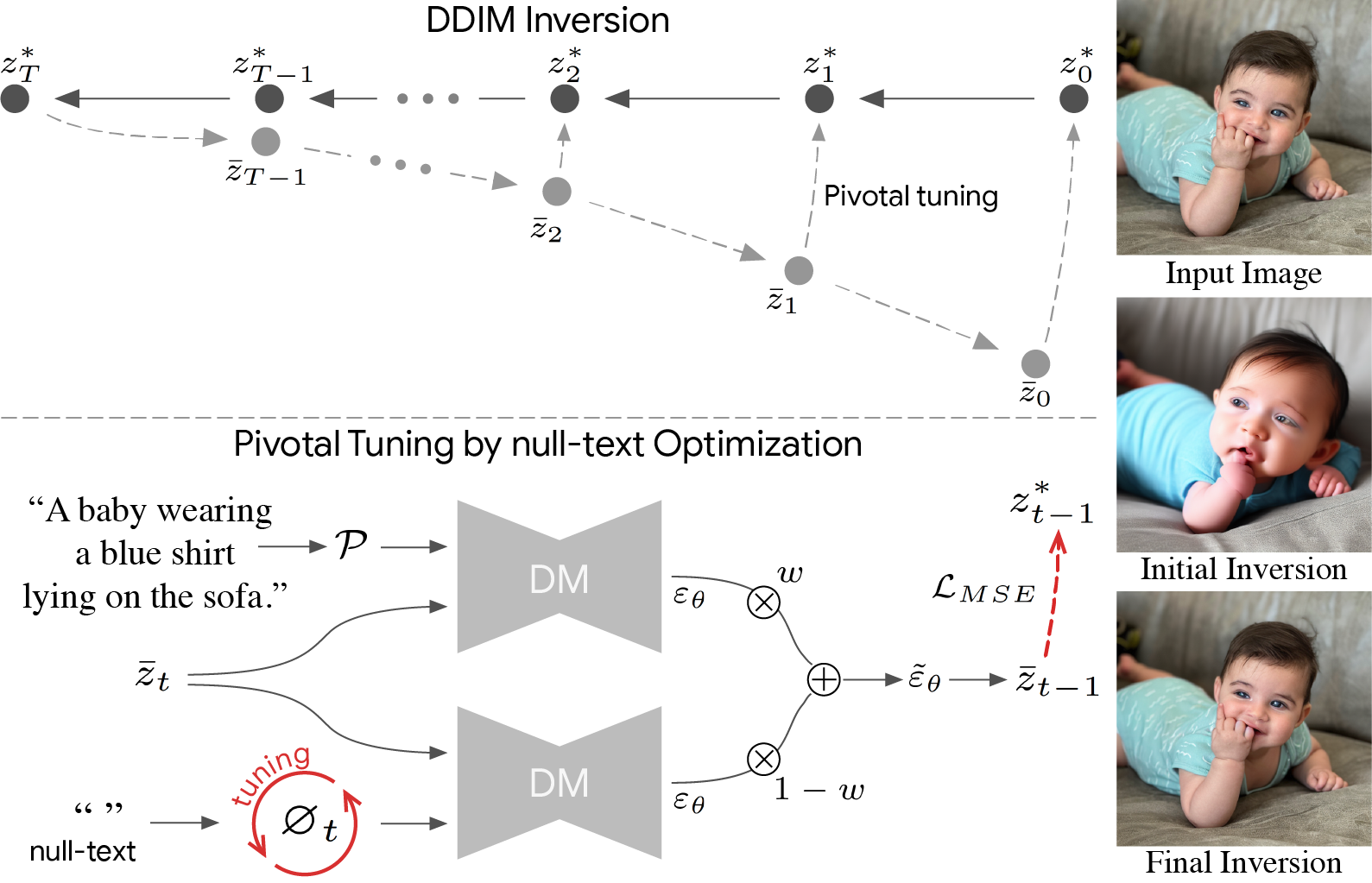
null-text optimization for timestamp t. Recall that classifier-free guidance consists of performing the noise prediction twice – using text condition embedding and unconditionally using null-text embedding ∅ (bottom-left). Then, these are extrapolated with guidance scale w (middle). We optimize only the unconditional embeddings ∅t by employing a reconstruction MSE loss (in red) between the predicated latent code to the pivot.
Inversion with Different Captions
- The Attention maps still capture the caption tokens

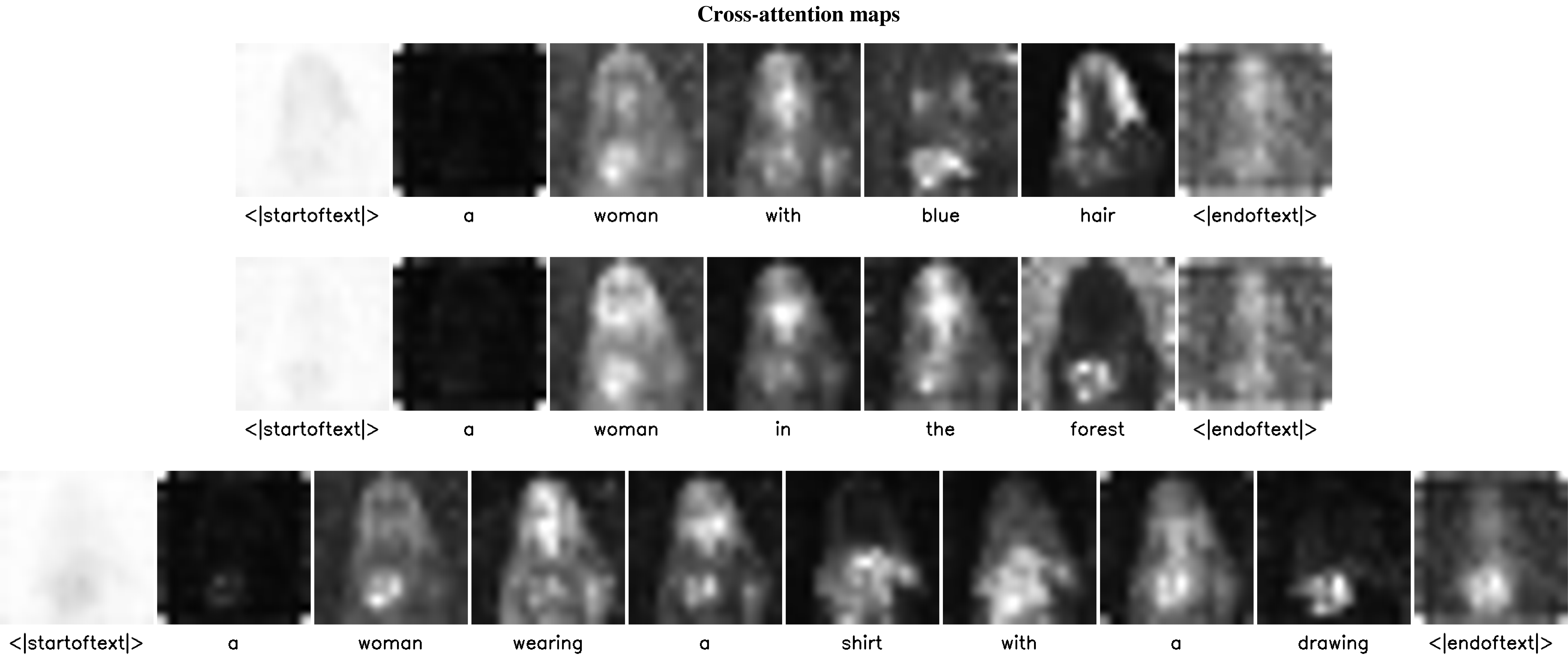
Some experiments to test the effectiveness of attention map capture
- Images are ground truth image | vq-autoencoder reconstruction | null-text inverted image
- Attention map results of 16 resolution and 32 resolution respectively

Inversion Ablation






