
JEPA (Joint-Embedding Predictive Architecture)
JEPA
JEPA (Joint-Embedding Predictive Architecture) is a self-supervised learning method that predicts abstract representations of missing data (targets) from visible data (context) in a shared latent space, avoiding direct pixel prediction or contrastive forces, leading to more semantic, stable, and efficient learning for tasks like image and video understanding by focusing on core concepts rather than pixel details.
- Predicting in representation space avoids wasting compute on pixel-level noise
- Higher semantic quality, better transferability, and more scalable training.
JEPA vs Contrastive Learning
JEPA (Joint Embedding Predictive Architecture) V.S. Contrastive Learning (SimCLR / CLIP / CPC etc.)
| Dimension | JEPA | Contrastive Learning |
|---|---|---|
| Core question | Can I predict the latent state of this world from context? | Can I tell which representations belong together? |
| Prediction target | Latent embedding of the same sample (masked region, future state, other part) | Latent embedding of another view / modality / sample |
| Target definition | Absolute (fixed target encoder output) | Relative (defined against negatives or batch statistics) |
| Negatives | N/A | Explicit (SimCLR, CLIP) or implicit (BYOL/VICReg) |
| Collapse prevention | Structural asymmetry (predictor + stop-grad target) | Geometric repulsion, variance/covariance regularization |
| Role of augmentation | Optional, auxiliary | Critical (defines invariances) |
| Learning signal | Predictive consistency across latent space | Discriminative separation in embedding space |
| What is preserved | Predictable structure, dynamics, latent state variables | Invariance under augmentation / modality changes |
| What is discarded | Unpredictable or stochastic details | Augmentation-variant details |
| Reconstruction level | Latent (no pixels) | None (or implicit via alignment) |
| Loss type | Regression in latent space (e.g., MSE / cosine) | Contrastive or alignment + uniformity losses |
| Batch size dependence | Low | Often high (for stable negatives) |
| Representation geometry | Not explicitly shaped | Explicitly shaped (clusters, margins, uniformity) |
| Temporal modeling | Natural fit (future latent prediction) | Awkward / indirect |
| Causal interpretability | Higher (state-like representations) | Lower (instance-discriminative) |
| Typical failure mode | Over-abstract / miss fine details | Shortcut invariances, texture bias |
| Best suited for | World models, physics, video dynamics, planning | Retrieval, alignment, recognition, multimodal matching |
| Example | I-JEPA, V-JEPA, DINOv2-JEPA-like | SimCLR, MoCo, CLIP, VICReg |
I‑JEPA: Learning from Images
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture (2023)
V‑JEPA: Learning from Video
Revisiting Feature Prediction for Learning Visual Representations from Video (2024)
A self-supervised video representation learning method that learns purely by predicting masked video features, and shows it yields strong, label-efficient representations for many video and image tasks without using labels, text, or pixel reconstruction.
- V-JEPA uses a Joint-Embedding Predictive Architecture where an encoder and a predictor learn to predict the representation of masked spatio-temporal regions y from visible regions x, conditioned on the mask geometry. (Figure 2)
- The model operates in feature space, not pixel space: a ViT-based video encoder processes a heavily masked clip (∼90% tokens masked via a “multi-block” strategy), and a narrow transformer predictor outputs representations for masked tokens that are trained to match a stop‑gradient EMA “target” encoder using an L1 loss. (Figure 3)
- Inputs are short clips (16 frames at 224 or 384 resolution) tokenized by 3D patches; training is done on a large unlabeled mixture of public video datasets (VideoMix2M, ~2M videos from HowTo100M, Kinetics-400/600/700, SSv2).
Core Findings
- Predicting features instead of pixels consistently improves downstream performance in both frozen evaluation and fine-tuning compared to masked autoencoding in pixel space, under matched compute.
- Larger and more diverse pretraining data improves average performance, and attentive (cross-attention) pooling over frozen features significantly boosts results relative to simple average pooling.
- A high spatio‑temporal masking ratio and the proposed multi-block masking (combining short- and long-range blocks) are crucial; alternative masking schemes like random tubes or causal masks perform worse.
Label efficiency and qualitative analysis
- With few labeled examples (5–50% of K400/SSv2 labels), V-JEPA’s performance drops less than competing video methods, indicating more label-efficient representations.
- A diffusion-based decoder trained on top of frozen V-JEPA predictions shows that predicted features encode coherent structure and motion: generated pixels over masked regions respect object permanence and plausible motion, even though V-JEPA itself is not generative. (Figure 6a)



Physics understanding study on V-JEPA
Intuitive physics understanding emerges from self-supervised pretraining on natural videos (2025)
The paper shows that a specific kind of self-supervised video model, V-JEPA, develops a non-trivial, human-like understanding of intuitive physics simply by predicting masked parts of natural videos in an internal representation space, without any hard-coded physics or task-specific supervision.
- The authors ask whether intuitive physics (object permanence, continuity, gravity, etc.) can emerge in general-purpose deep networks without built-in “core knowledge” modules.
- They study a video Joint Embedding Predictive Architecture (V-JEPA) that learns by predicting masked regions of videos in latent space, then use violation-of-expectation tests (measuring “surprise” as prediction error) to probe its physics understanding zero-shot.
- For a given video, they slide a window of M past frames and predict the latent representations of the next N future frames, then compare prediction vs actual latent reps to get a surprise time series St.
- They aggregate this into a single scalar per video (average or max surprise over time), which is the surprise score used for VOE.
Core Findings
- V-JEPA distinguishes physically possible vs impossible videos with high zero-shot accuracy, reaching about 98% on IntPhys, 66% on GRASP, and 62% on InfLevel-lab in pairwise plausibility classification.
- Comparable video models that predict in pixel space (VideoMAEv2) and multimodal LLMs (e.g., Qwen2-VL, Gemini 1.5 Pro) stay near chance or only slightly above untrained networks on the same benchmarks.
- Across properties, V-JEPA significantly outperforms untrained networks on many concepts (object permanence, continuity, shape constancy, gravity, support, inertia), but shows limited gains for some interaction-heavy properties (color constancy in some setups, solidity, collision).
What matters for emergence
- Changing the pretraining objective from block masking to causal block masking or random masking affects performance only modestly; predicting in an abstract representation space appears more critical than the exact masking scheme.
- Training data type matters: tutorial-style HowTo100M videos yield better physics performance than pure motion (SSv2) or action (Kinetics) alone, but even with only ~128 hours of unique video from HowTo100M the model remains well above chance.
- Model scale helps but is not strictly required: even a ~115M-parameter V-JEPA attains >85% accuracy on IntPhys pairwise tasks, indicating that relatively modest models can acquire robust intuitive physics.
Limitations and implications
- V-JEPA struggles more with properties that rely on rare or complex object interactions (e.g., collisions, some solidity and gravity setups in InfLevel) and with scenarios requiring long-term memory or contextualizing events, as in InfLevel-lab’s pre-context videos.
- Current JEPA models process only short clips (≈3–4 seconds) and cannot condition on actions or interact with the environment, limiting their ability to learn richer causal and interactive physics.
- The results challenge strong versions of the “core knowledge” hypothesis for artificial systems, suggesting that a general latent prediction principle can produce meaningful intuitive physics, and may provide a promising foundation for future world-simulator and video generation models.
Why prediction error = “surprise”
- V-JEPA is trained only to predict missing or future latent representations of videos; the loss is the distance between predicted and actual representations, so high error means “the future did not match what my world-model expected.”
- In VOE terms, that prediction error becomes a surprise signal: if a clip contains an impossible event (object vanishes, passes through wall, etc.), the model’s latent prediction fails badly there, raising the scalar surprise score for that video.
- In infant VOE, one does not directly label events as impossible; experimenters just measure which event elicits more “surprise” (longer looking, etc.) and interpret higher surprise as detecting a violation.
- The paper mirrors this: for each matched pair, whichever video yields higher surprise (prediction error aggregated over time) is taken as the “impossible” one, so the model’s physics knowledge is inferred from how its expectations are violated, not from an explicit binary impossibility label.
V-JEPA 2
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning (2025)
A large self-supervised video model trained on over 1 million hours of internet video plus images
- V-JEPA 2 uses a joint-embedding predictive architecture (JEPA) that predicts masked video regions in a learned feature space rather than generating pixels, making it focus on predictable structure like object motion instead of fine visual details.
- After this large-scale “action-free” pretraining, a smaller action-conditioned head (V-JEPA 2-AC) is trained on about 62 hours of Franka robot videos to predict future features given actions, enabling planning for real robot manipulation from a single RGB camera.
- Architecture
- The model uses ViT-based encoders and predictors with rotary 3D positional embeddings, patchifying videos into spatiotemporal tubelets and learning via a mask-denoising objective in feature space.
V-JEPA 2 vs V-JEPA 1
V-JEPA 2 vs VideoMAE
| Aspect | V-JEPA 2 | VideoMAE |
|---|---|---|
| Core objective | Predicts masked video regions in feature space using a joint-embedding predictive objective | Reconstructs heavily masked video pixels with a masked autoencoding objective |
| Prediction target | Teacher embeddings of masked spatiotemporal tubelets (latent features) | Raw RGB pixels of masked video cubes |
| Architecture | ViT encoder + small predictor; EMA teacher–student JEPA setup with 3D tubelets. | ViT encoder + lightweight decoder for pixel reconstruction with tube masking. |
| Masking strategy | Structured spatiotemporal masking of tubelets for feature prediction. | Extremely high random tube masking (≈90–95% of patches) for reconstruction. |
| Data scale / regime | Trained on >1M hours of internet video + images (VideoMix22M etc.) | Designed for data-efficient pretraining; strong results even on smaller datasets. |
| Typical evaluation | Frozen or lightly tuned probes, video QA with LLM alignment. | Fine-tuning accuracy on benchmarks like Kinetics and Something-Something v2. |
MC-JEPA: Learning from Motion and Content
MC-JEPA is a joint-embedding predictive architecture and self-supervised learning approach to jointly learn optical flow and content features within a shared encoder, demonstrating that the two associated objectives; the optical flow estima- tion objective and the self-supervised learning objective; benefit from each other and thus learn content features that incorporate motion information.
- Jointly learning motion features by
- using self-supervised optical flow estimation from videos as a pretext task, and
- content features with general self-supervised learning.

VL-JEPA
VL-JEPA: Joint Embedding Predictive Architecture for Vision-language (2025)
Others
IWM: Image World Models
Learning and Leveraging World Models in Visual Representation Learning (2024)
- An approach that goes beyond masked image modeling and learns to predict the effect of global photometric transformations in latent space.
Motivation: seek to explore whether learning and leveraging world models can also be benificial in visual representation learning
- it is learning a function in feature space that maps (source features, action) → target features
- The predictor learns the operator in representation space
VideoMAE
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training (2022)
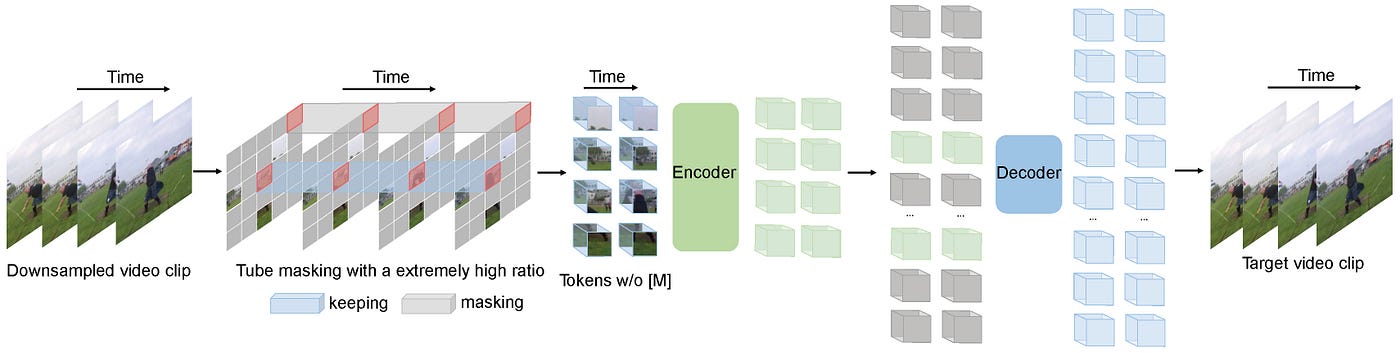
Introduces a simple, pixel-level masked video autoencoder using plain ViT with tube masking and extremely high masking ratios.
- a masked autoencoder method that makes video transformers highly data-efficient for self-supervised video pre-training by masking most of the input video and reconstructing it.
- VideoMAE extends masked autoencoders from images to videos by masking 90–95% of spatiotemporal “cubes” and reconstructing pixels with an asymmetric encoder–decoder based on a vanilla ViT backbone.
- encoder is much larger and heavier than the decoder, both in depth and width, and also sees far fewer tokens.
- The asymmetric design is used to make pre-training both efficient and representation-focused, while keeping reconstruction as a cheap helper task.
- A key design is tube masking, where the same spatial mask is applied across all frames, making it harder to trivially copy information from adjacent frames and forcing high-level spatiotemporal reasoning.
- VideoMAE extends masked autoencoders from images to videos by masking 90–95% of spatiotemporal “cubes” and reconstructing pixels with an asymmetric encoder–decoder based on a vanilla ViT backbone.
Architecture
- Input clips are temporally downsampled (e.g., stride 2–4), then split into 3D cubes (e.g., 2×16×162×16×16) to form tokens for a ViT encoder with joint space-time attention; only unmasked tokens go into the encoder, reducing computation.
- A lightweight transformer decoder (e.g., 4 blocks, narrower than the encoder) reconstructs masked cubes in pixel space using an MSE loss over masked tokens.
- Ablations show: 4 decoder blocks, 90% tube masking, reconstructing the downsampled clip itself, and MSE loss yield the best trade-offs.
Demonstrates that this design is both computationally efficient and data-efficient, enabling strong video transformers on small and large datasets without external pre-training data, and yielding highly transferable representations for classification and detection tasks.
- Data efficiency: VideoMAE can train ViT-B from scratch on relatively small datasets (3–4k videos) and still achieve strong accuracy (e.g., ~62.6% on HMDB51, 91.3% on UCF101), outperforming scratch and MoCo v3 contrastive pre-training.
- Transferability and downstream tasks: Representations learned on Kinetics-400 transfer well to SSV2, UCF101, HMDB51 and AVA action detection, generally outperforming MoCo v3
- When there is domain shift between pre-training and target datasets, in-domain pre-training with fewer but higher-quality videos can outperform larger, out-of-domain pre-training sets, suggesting data quality matters more than quantity for SSVP.