
Paper Review - FramePack and Anti-drifting Sampling
Preliminary
Let’s revisit how modern Video Diffusion Model works.
1 | +-------------------------+ +------------------------------+ |
✅1. VAE Encoding — Compression stage
Compress each input frame (or clip) into a smaller latent space using a VAE (Variational Autoencoder).
- From image (e.g., 480×832×3)
→ to latent map (e.g., 60×104×4) via encoder. - Done per frame, or per chunk (in video setting).
This significantly reduces spatial resolution, making the next steps computationally feasible.
📜 “All definitions of frames and pixels refer to latent representations, as most modern models operate in latent space.”
✅ 2. Patchify + Tokenization — Convert into tokens
- Apply a 3D patchify kernel, like (1, 2, 2) → divides the latent map into non-overlapping patches.
- Each patch becomes a token, a vector (e.g., 768-d).
- This is how the Transformer sees the input — as a sequence of tokens.
✅ 3. Diffusion Transformer (DiT) — Denoising via attention
This is the core model, usually a modified Transformer that:
- Conditions on input tokens (from past frames).
- Predicts the denoised version of the current latent (or future frames).
It operates in the latent space instead of raw pixel space, which is much more efficient.
✅ 4. Denoising Scheduler (Diffusion Process)
Use DDPM/DDIM/EDM-like schedulers to iteratively denoise a latent.
- Start from Gaussian noise (for generation)
- Each step tries to remove noise, guided by the DiT’s prediction
✅ 5. VAE Decoder — Reconstruct pixel frames
- After diffusion, the final latent is passed to the VAE decoder.
- This reconstructs full-resolution video frames (e.g., 480×832×3).
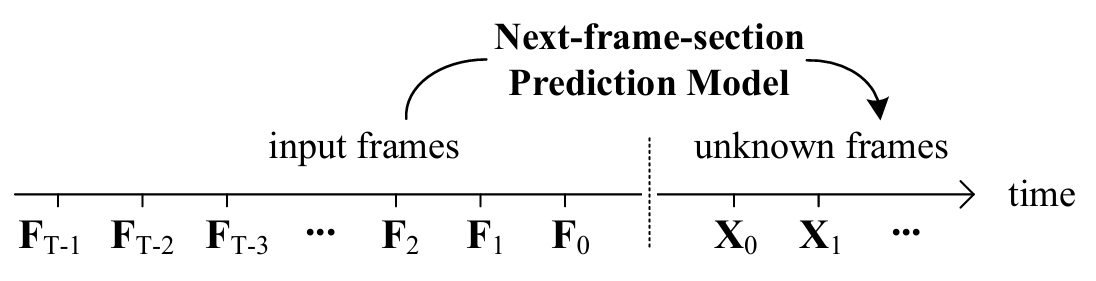
Packing Input Frame Context in Next-Frame Prediction Models for Video Generation
Abstract:
We present a neural network structure, FramePack, to train next-frame (or nextframe-section) prediction models for video generation. The FramePack compresses input frames to make the transformer context length a fixed number regardless of the video length. As a result, we are able to process a large number of frames using video diffusion with computation bottleneck similar to image diffusion. This also makes the training video batch sizes significantly higher (batch sizes become comparable to image diffusion training). We also propose an anti-drifting sampling method that generates frames in inverted temporal order with early-established endpoints to avoid exposure bias (error accumulation over iterations). Finally, we show that existing video diffusion models can be finetuned with FramePack, and their visual quality may be improved because the next-frame prediction supports more balanced diffusion schedulers with less extreme flow shift timesteps.
Adventages (according to the project page):
- Diffuse thousands of frames at full fps-30 with 13B models using 6GB laptop GPU memory.
- Finetune 13B video model at batch size 64 on a single 8xA100/H100 node for personal/lab experiments.
- Personal RTX 4090 generates at speed 2.5 seconds/frame (unoptimized) or 1.5 seconds/frame (teacache).
- No timestep distillation.
- Video diffusion, but feels like image diffusion.
My thought: It can be a very useful structure. Since a video model can be popular models like :
- HunyuanVideo
- Wan 2.1
What is the paper trying to tackle?
Forgeting Problem (Sementic Consistency Degradation)
What’s the issue?
Next-frame prediction models struggle to remember earlier frames, leading to a loss of temporal coherence.
“‘Forgetting’ refers to the fading of memory as the model struggles to remember earlier content and maintain consistent temporal dependencies” (Introduction)
Why does it happen?
Transformer-based video models have limited memory and compute power. Encoding too many frames becomes infeasible due to attention complexity.
“The forgetting problem leads to a naive solution to encode more frames, but this quickly becomes computationally intractable due to the quadratic attention complexity of transformers…” (Introduction)
My thought: valid. This happened in both video generation and editing.
Drifting Problem (Perceptual Quality Degradation)
What’s the issue?
The generated video gradually degrades in quality over time.
“‘Drifting’ refers to the iterative degradation of visual quality due to error accumulation over time (also called exposure bias).” (Introduction)
Why is it hard to fix?
Attempts to fix forgetting often make drifting worse—and vice versa. It’s a trade-off.
“any method that mitigates forgetting by enhancing memory may also make error accumulation/propagation faster, thereby exacerbating drifting; any method that reduces drifting by interrupting error propagation and weakening the temporal dependencies (e.g., masking or re-noising the history) may also worsen the forgetting. This essential trade-off hinders the scalability of next-frame prediction models.” (Introduction)
Proposed Solution (Overview)
The paper introduces methods to simultaneously address forgetting and drifting, a challenge most prior work fails to balance.
FramePack (solves forgetting)
How it works: Compress input frames based on importance so the model can handle longer histories without running out of memory.
“We propose FramePack as an anti-forgetting memory structure… by compressing input frames based on their relative importance, ensuring the total transformer context length converges to a fixed upper bound regardless of video duration.” (Introduction)
This allows the model to look further back in time, without blowing up compute costs:
“This enables the model to encode significantly more frames without increasing the computational bottleneck…” (Page 2)
Anti-drifting Sampling (solves drifting)
How it works: Break causal prediction by sampling frames in reverse order or from endpoints inward, using known “anchor” frames to reduce error accumulation.
“We propose anti-drifting sampling methods that break the causal prediction chain and incorporate bi-directional context. These methods include generating endpoint frames before filling intermediate content, and an inverted temporal sampling approach…” (Introduction), “We show that these methods effectively reduce the occurrence of errors and prevent their propagation.” (Introduction)
Method
FramePack (solves forgetting)
Goal: Solve the forgetting problem by encoding more history frames without exploding context length.
“We propose FramePack as an anti-forgetting memory structure… ensuring the total transformer context length converges to a fixed upper bound regardless of video duration.” — (Section 3.1)
🧠 Key Idea:
- Not all frames are equally important for predicting the next frame.
- More recent frames are more important for predicting the next.
- Use progressive compression on older frames to fit more into fixed-length transformer context.
“We observe that the input frames have different importance when predicting the next frame… Without loss of generality, we consider a simple case where the temporal proximity reflects importance.” — (Section 3.1)
Math Explaination:
Each input frame is assigned a compression length:
where
- is context length of an uncompressed frame (e.g., around 1560 tokens for a 480p frame)
- is the compression factor, usually 2
- is how far the frame is in the past (0 = most recent)
1 | # Simple pseudocode |
The length function determines each frame’s context length after VAE encoding and transformer patchifying, applying progressive compression to less important frames
Total Context Length Computation can be computed by adding up all compressed frames:
Where:
- = number of future frames to predict (typically small like 1)
- = number of past frames provided
This sum is a geometric progression. As , the total context length converges to a constant, meaning it won’t blow up with more frames.
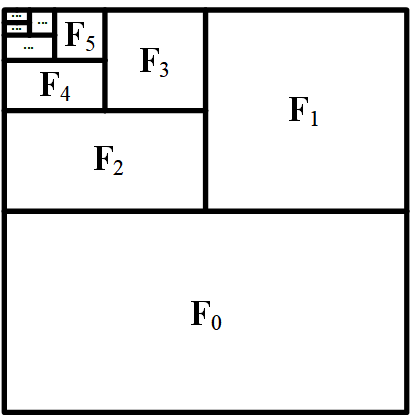
Practical Implementation
- They use 3D patchify kernels to compress frames.
- e.g., (2,4,4) → downsample across height and width
- Different compression levels use independent projection layers to stabilize learning.
- Hardware prefers power-of-2 compression (like 2×, 4×, 8×) for efficiency.
“The patchifying operations in most DiTs are 3D, and we denote the 3D kernel as (pf, ph, pw) representing the steps in frame number, height, and width.”
(Section 3.1)
“Empirical evidence shows that using independent parameters for the different input projections at multiple compression rates facilitates stabilized learning.”
(Section 3.1)
Handling “Tail Frames” (Extremely Compressed, least important frames)
When frames are so compressed that they become very small (almost 1 pixel), three options are proposed:
- Delete them
- Increase context length slightly per frame
- Global average pooling
“In our tests, the visual differences between these options are relatively negligible. We note that the tail refers to the least important frames, not always the oldest frames (in some cases, we can assign old frames with higher importance).”
(Section 3.1)
RoPE Alignment
Since frames are compressed differently, positional encodings (RoPE) need to align across different compression rates.
- They solve it by average-pooling the RoPE phases to match the compression.
“When encoding inputs with different compression kernels, the different context lengths require RoPE (Rotary Position Embedding) alignment.”
(Section 3.1)
A Short summary of FramePack (solves forgetting):
- FramePack requires training.
| What | Why | How |
|---|---|---|
| Compress older frames more | To control memory and allow longer histories | Geometric compression: ( \phi(F_i) = L_f / \lambda^i ) |
| Bound total context length | To avoid transformer explosion | Converges to constant as ( T \to \infty ) |
| Different patch sizes for different frames | To stabilize and optimize compression | Use independent kernels (e.g., (2,4,4), (4,8,8)) |
| Tail frame handling | To manage extremely compressed frames | Delete / Minimal addition / Global average pooling |
| RoPE adjustment | To maintain positional information correctly | Average pool RoPE phases |
Anti-drifting Sampling
Goal: Solve the drifting problem by using future frames as anchors — predict towards a known good frame. This allows access to bi-directional context (both earlier and later frames)
“We show that providing access to future frames (even a single future frame) will get rid of drifting."
(Section 3.3)
🧠 Key Idea:
- Instead of always predicting frame from past frames up to , break the strict causality by giving the model bi-directional context:
- Predict frames between two known points (start and end frames)
- Or predict backward (from future frames back toward the start)
- This way, even if errors happen, the model has a “good” frame nearby to anchor to, reducing long-term drift.
Math Explaination
Traditional Vanilla Sampling (Causal) :
- At time step , model predicts frame using frames .
- Only past context available.
- This causes cumulative error:
(Where is the generator model.)
Because each predicted frame might have errors, those errors get fed into future predictions, snowballing drift.
Anti-drifting Sampling (Bidirectional) and Inverted anti-drifting (Reverse Order):
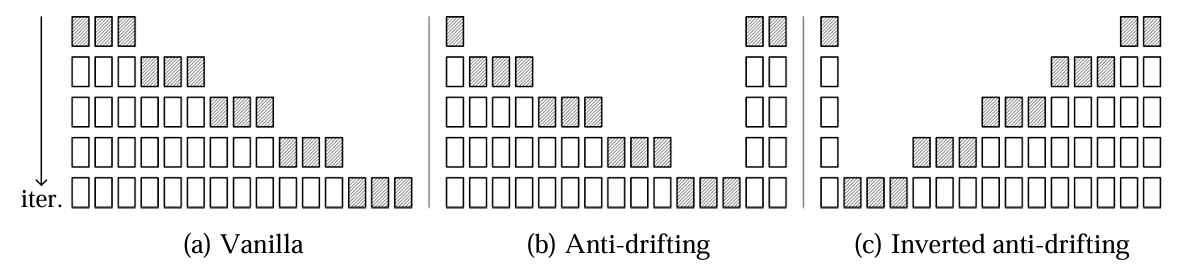
In Anti-drifting sampling:
- Generate start and end frames first: and are fixed.
- Then predict middle frames recursively using both sides as anchors.
“The first iteration simultaneously generates both beginning and ending sections, while subsequent iterations fill the gaps between these anchors.”
— Section 3.3, explanation of Fig 2 (b)
In Inverted anti-drifting (Reverse Order):
- Start from the last frame (known or cleanly generated)
- Then predict backward one frame at a time.
Frame is generated based on , then based on , and so on.
Why useful?
In tasks like image-to-video, the starting frame (user image) is highest quality so working backward from it preserves quality better.
“We discuss an important variant by inverting the sampling order in Fig. 2-(b) into Fig. 2-©. This approach is effective for image-to-video generation because it can treat the user input as a high-quality first frame, and continuously refines generations to approximate the user frame (which is unlike Fig. 2-(b) that does not approximate the first frame), leading to overall high-quality videos.”
— Section 3.3, explanation of Fig 2 ©
- Anti-drifting sampling is mostly a training-free modification — but performs best when fine-tuned with it.
- Basically Inverted Anti-drifting sampling happens recursively across sections, which Each latent section covers a small window of frames.
Soft Appending in
Not discussed in the paper, but appeared in implementation code
Instead of “hard cut and paste”, FramePack softly blends the newly generated section into the previous one over overlapping frames.
when defining sections, there are intentionally overlapping frames.
- Ensure transition between sections is smooth.
- basically alpha blending — but applied over time across video frames in the temporal dimension.
1 | # Example |
Findings
| Category | Best Setting | Trade-off |
|---|---|---|
| Best sampling method | Inverted Anti-drifting Sampling | Slightly lower “Dynamic” (motion magnitude) score |
| Best number of frames per step | 9 frames per section | Larger memory usage during inference |
| Overall performance | Best across clarity, drifting metrics, and human evaluation | None significant |
| Visual stability | Best with inverted sampling | Slightly less visually aggressive motion |
“The inverted anti-drifting sampling method achieves the best results in 5 out of 7 metrics, while other sampling methods achieve at most a single best metric.”
— Section 4.4, first paragraph
“The inverted anti-drifting sampling achieves the best performance in all drifting metrics.”
— Section 4.4, first paragraph
“Human evaluations indicate that generating 9 frames per section yields better perception than generating 1 or 4 frames, as evidenced by the higher ELO scores…”
— Section 4.4, first paragraph
Related Works mentioned
Anti-forgetting & Anti-drifting
| Technique/Method | Key Idea | Representative Works |
|---|---|---|
| Noise Scheduling & Augmentation | Add noise to history frames to mitigate exposure bias and drift | DiffusionForcing, RollingDiffusion |
| Classifier-Free Guidance (CFG) | Mask/noise the history side in guidance to explore the forgetting-drifting trade-off | HistoryGuidance |
| Anchor Frame Planning | Use specific frames as references to stabilize generation | StreamingT2V, ART-V |
| Memory Trade-off Studies | Discuss the trade-off between strong memory and error propagation | CausVid |
Long Video Generation
| Technique/Method | Key Idea | Representative Works |
|---|---|---|
| Latent Diffusion | Generate long videos from compressed latent representations | LVDM, Phenaki |
| Multi-text Conditioning | Generate coherent multi-scene long videos from multiple prompts | Gen-L-Video, MEVG |
| Noise Rescheduling | Extend pre-trained models with test-time tuning | FreeNoise, TTT |
| Hierarchical/GPT-style Architectures | Use multi-level or autoregressive generation to scale length | NUWA-XL, ViD-GPT, DiTCtrl |
| Distributed Generation | Parallelized or chunked generation for scalability | Video-Infinity |
Efficient Architectures for Video Generation
| Technique/Method | Key Idea | Representative Works |
|---|---|---|
| Linear/Sparse Attention | Reduce computational cost of attention mechanisms | Linformer, Performer |
| Low-bit Computation | Quantize model weights/activations for faster inference | Q-Diffusion, SageAttention |
| Hidden State Caching | Cache intermediate states across timesteps to avoid redundancy | TimestepCache, FasterCache |
| Knowledge Distillation | Use a smaller or faster student model guided by a larger model | Consistency Models, LCM |
Final Comparison
| Component | Vanilla Video Diffusion | FramePack-enhanced Video Diffusion |
|---|---|---|
| VAE Encoder | ✅ Compresses each frame into latent space | ✅ Same |
| Patchify | ✅ Uniform patch size for all frames (e.g., 2×2) | ✅ Adaptive patch size (progressive compression by frame importance) |
| Compression Strategy | ❌ No prioritization of frames | ✅ Recent frames get high resolution; older frames are compressed |
| Transformer Context | ❌ Grows linearly with frame count | ✅ Bounded by geometric progression ( ) |
| Sampling Order | ❌ Causal only (predict frame-by-frame forward) | ✅ Supports reverse or bidirectional sampling (anti-drifting) |
| Error Accumulation | ❌ High — exposure bias, errors propagate | ✅ Low — anchored endpoints reduce drift |
| Max Frames Supported | ❌ Limited due to compute cost | ✅ Supports long videos (e.g., 64+ frames) |
| Batch Size (Training) | ❌ Small, due to large token count | ✅ Large — similar to image diffusion training |
| Temporal Modeling | ❌ Flat memory structure | ✅ Hierarchical, context-aware memory structure |
| Goal | Basic video generation | Robust, scalable, memory-efficient next-frame prediction |
Paper Discussion





