
Paper Review - ColorPeel
ColorPeel
Paper: ColorPeel: Color Prompt Learning with Diffusion Models via Color and Shape Disentanglement (ECCV 2024)
“disentanglement” refers to the process of decoupling shapes and colors from a set of auto-generated colored geometries in this paper.
This paper improves disentanglement:
- Introduced a dataset consists on basic geometric objects in precise RGB code color
- Finetuned T2I model (SD 1.4) on the dataset with an auxiliary special loss function
- Cross Attention Alignment (CAA) Loss
- Resulting precise control on rgb color

Method
We denote
- color concepts as
- shape concepts as
The prompt template will be “A photo of shape with color”, and some text varient then paired with the dataset of the basic geometric objects in shape with precise RGB code color
Then directly optimze the new tokens (, ) and the Stable Diffusion UNet by minimizing the Latent Diffusion Model (LDM) Loss:
However, this method failed to correctly disentangle color from the shape. It is because:
- the misalignment between color attention and shape attention in the model’s cross-attention maps.
Therefore ColorPeel proposed the Cross Attention Alignment (CAA) Loss to achieve agreement between these cross-attentions, as defined by the cosine similarity between the cross-attention maps:
- measures the cosine similarity between the attention maps of color and shape.
- cosine similarity measures how similar two vectors are. Higher cosine similarity means the vectors are more aligned.
- By minimizing , it encourages higher similarity between the attention maps for color and shape
- the model focuses on the correct aspects for both color and shape simultaneously.
How does it achieve disentanglement?
Its strengthing the cross attention alignment to achieve disentanglement.
- It ensure that both color and shape attentions are directed towards the correct regions/features of the image.
- avoid color information incorrectly attributed to shape features
So the new loss become
- seems to achieve the best result.
Overall
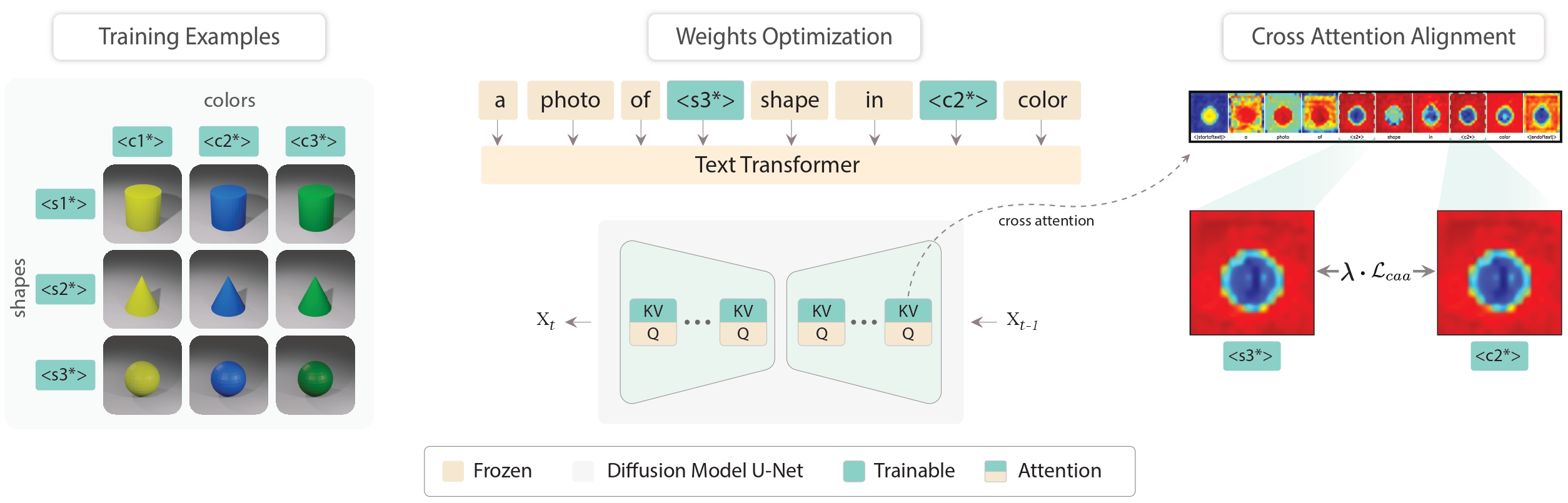
Illustration of the ColorPeel method.
Firstly, instance images along with the templates are generated, given the user-provided RGB or color coordinates.
Next, new modifier tokens are introduced, i.e., and which correspond to shapes and colors to ensure the disentanglement of shape from color.
Following Custom Diffusion, the key and value projection matrices in the diffusion model cross-attention layers are optimized along with the modifier tokens while training.
Cross attention alignment is introduced to enforce the color and shape cross-attentions disentanglement.





