Data mining is defined as the process of discovering patterns in data.
It uses pattern recognition and machine learning techniques to identify trends within a sample data set.
The process must be automatic or (more usually) semi-automatic.
The patterns discovered must be meaningful
in that they lead to some advantage, usually an economic advantage.
Data mining can provide huge paybacks for companies who have made a significant investment in data warehousing.
Data Warehouse for Data Mining
The existence of a data warehouse is not a prerequisite for data mining.
In practice, the task of data mining, especially for some large companies, is made a lot easier by having access to a data warehouse.
The transformations of data when a warehouse is created
is a pre-processing step for data mining.
How does the data mining and data warehousing work together?
Data warehousing can be used for analyzing the business needs by storing data in a meaningful form.
Using Data mining, one can forecast the business needs. Data warehouse can act as a source of this forecasting.
Example Applications of Data Mining
Retail / Marketing
Banking
Insurance
Medicine
Scientific and Engineering Applications
Software for Data Mining
Weka
Free, based on Java
Provide access to SQL database using JDBC
Orange
Free, based on Python
Provide add on for text mining
Rattle GUI
Free, based on R
Apache Mahout
Free, based on Java
Work with Hadoop
For large scale data mining and big-data analytics
Microsft Analysis Services
Work with Microsoft SQL Server
Microsoft Azure Machine Learning Service
Provide predictive analysis and machine learning services on Microsoft’s cloud
Oracle Data Mining
Embed data mining within Oracle database
Machine Learning
Key Concept
Instances
Things to be classified, associated, or clustered.
Also called “examples” or tuples in database terminology
It is important to clean up the instances. Remove null values and missing values
Attributes
Each instance is characterized by its values on a fixed, predefined set of features or attributes
Attributes are columns in database tables
Numeric attributes are either real numbers or integer values
e.g., height of a person.
Nominal (categorical) attributes take on values in a pre-defined and finite set of possibilities
e.g., month of year, gender.
Math operations can be applied to numeric attributes, but not to nominal attributes.
Only comparison operations can be applied to nominal attributes.
Machine Learning Algorithms
1-of-N transformation
Most machine learning algorithms (e.g., SVM and artificial neural networks) can only work on real numbers instead of categorical or nominal attributes.
We can convert categorical attributes into real number
e.g. Temperature can be {hot, mild, cool}
Using a vector such that [1 0 0] as hot, [0 1 0] as mild, [0 0 1] as cool
Unsupervised vs Supervised
Unsupervised Learning
Used to group things
e.g. Clustering, Association
input are not labelled
without output label
e.g. used to decide Image is group 1 or group 2 or even group 3
Supervised Learning
Used to classify
e.g. Classification, Regression
input are labelled
with output label
e.g. used to classify Image is label 1 (smile) or label 2 (not smile)
Classification
Classification is a process of learning a function that
maps a data item into one of several pre-defined classes.
determine the class label of an unknown sample
Produce class labels as output.
Classification is used for or help decision making.
We will go through some popular classifiers.
Naïve-Bayes Classifier
Category: Supervised Learning - Classification
To find the probability of the class given an instance - Bayes’ Rule
Pr[H∣E]=Pr[E]Pr[E∣H]Pr[H]
Pr[H∣E] - Posterior
Pr[E∣H] - Likelihood
Pr[H] - Prior
Pr[E] - Evidence
Where H is the hypothesis (class) and E is the evidence (attributes) {E0, E1, …, En}
Assume that each feature Ei is conditionally independent of every other feature Ej for j not equals i, given the hypothesis H
The conditional distribution over the class variable H is
Pr[H∣E]=Pr[E]∏i=0nPr[Ei∣H]Pr[H]
Note:
Find the priors and likelihoods
Normalize the probabilities (make it into scale 0 to 1)
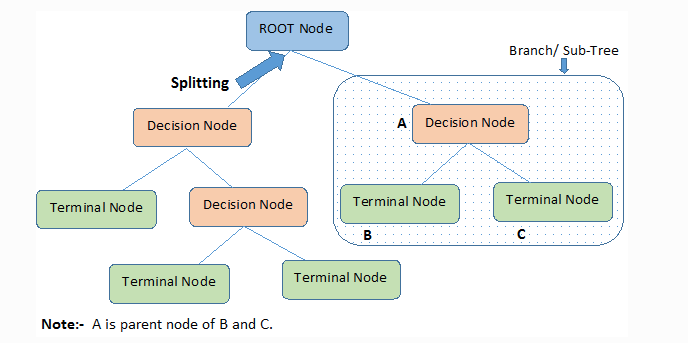
Choose the attribute with largest information gains as the node
Outlook is the winner. Therefore Outlook is selected as head node.
To continue to split, Repeat above steps to determine the child nodes until:
Data are all purest nodes
The final decision tree looks like this:
Support Vector Machines (SVM)
Category: Supervised Learning - Classification
Vector Machine
Might remove the influence of patterns that are far away from the decision boundary
their influence is usually small
May also select only a few important data point (called support vectors) and weight them differently.
With Support Vector Machine, We aim to find a decision plane that maximizes the margin.
Support Vector Machine
Decision plane is determined by the perpendicular of the 2 cloest vectors .
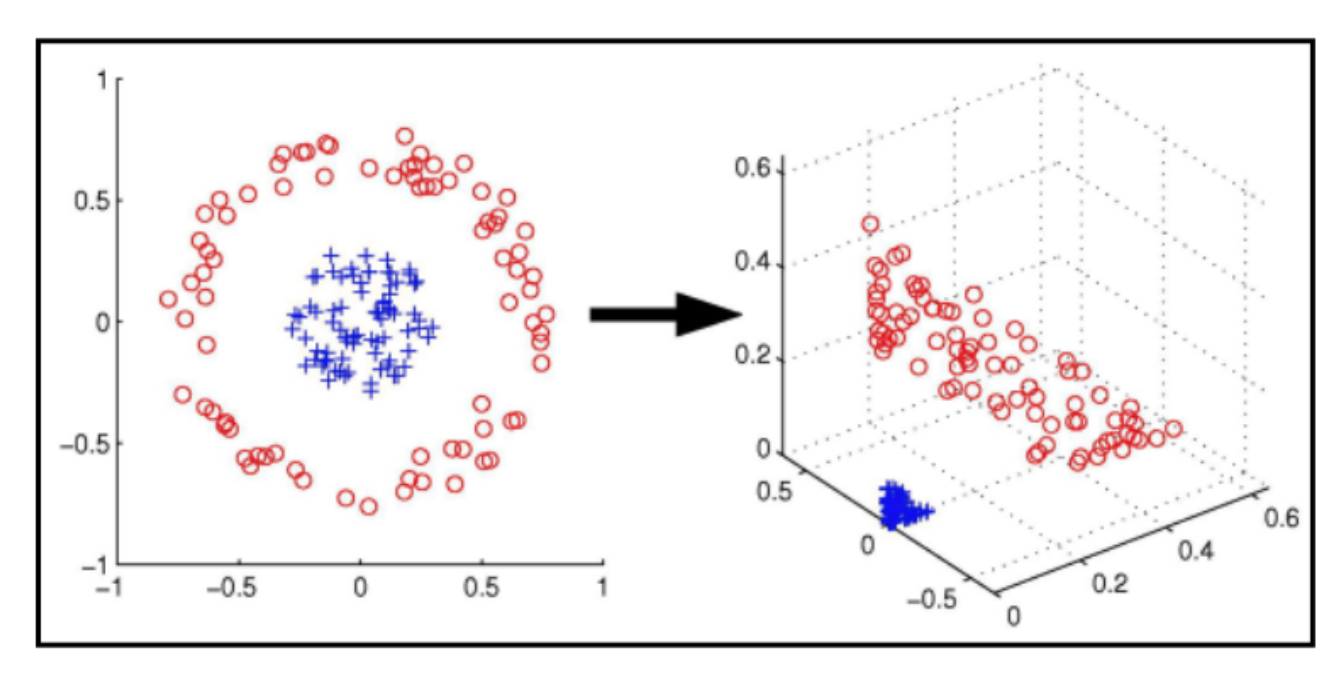
In case the training data X are not linearly separable, we may use a non-linear function ϕ(x) to map the data from the input space to a new high-dim space (called feature space ϕ) where data become linearly separable.
K-Nearest neighbour (K-Nn)
Category: Supervised Learning - Classification
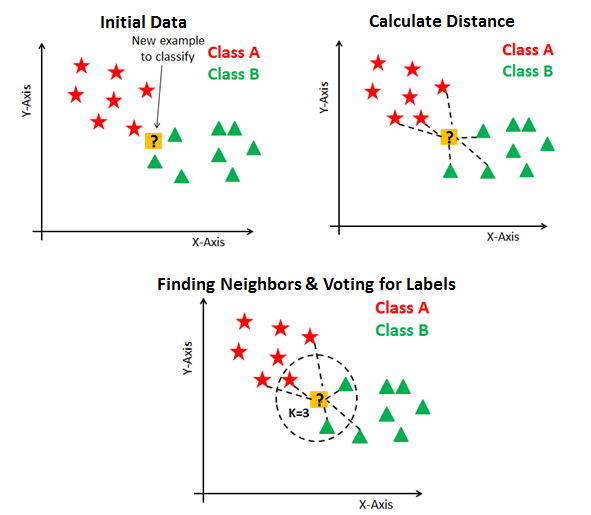
Assign K a value – preferably a small odd number
Find the closest number of K points
Assign the new point from the majority of classes.
TLDR : In a specific of range, The class of a new instance = the more Class in that range
Common Disadvantage using K-Nearest neighbour:
Classification will take a long time when the training data set is very large
due to the algorithm does not have training/learning stages
Neural Networks (NN)
Category: Supervised Learning - Classification
Feed-forward networks with several nonlinear hidden layers.
The output can be considered as the posterior probability of input, Pr(Class=i∣x) where x is the instance and Class is the possible labels.
Deep Learning = Neural Networks (NN) with A LOTS OF LAYERS IN THE MIDDLE
Prediction
Implement real-value mapping functions
Outcomes are numerical values
Linear regression
For modeling the relationship between a scalar dependent variable y and one or more explanatory variables denoted X.
Given an unknown multi-dimensional input x, the predicted output of a linear regression model is
f(x)=aTx+b
You assign weighting to the variables.
One of the real life example is Course Weightings.
Cluster Analysis
Divide input data into a number of groups
Used for finding groups of examples that belong together
Based on unsupervised learning
To group a set of data with similar characteristics to form clusters
The process of assigning samples to clusters is iterative.
each iteration, the samples in the clusters are redefined to better represent the structure of the data
After the clustering process, each cluster can be considered as a summary of a large number of samples.
Thus, they can help in making faster decisions. The clusters also help to identify different groups in the data.
Cluster analysis is widely used in market research when working with multivariate data from surveys. Market researchers use cluster analysis to partition the general population of consumers into market segments and to better understand the relationships between different groups of consumers/potential customers.
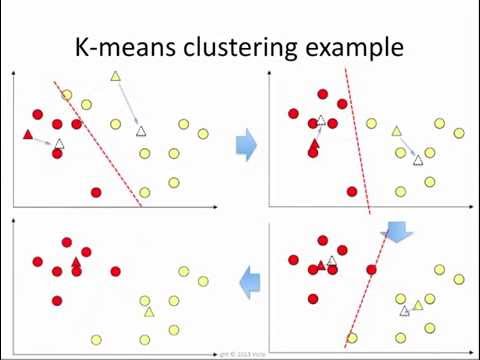
K-Means Clustering
An unsupervised learning methods
labels are not required.
TLDR : Keep changing the location of centre of a label. Some samples may change the label.
Associative-Rule Learning
Finding association rules among non-numeric attributes
Given a set of transactions, find rules that will predict the occurrence of an item based on the occurrences of other items in the transaction.
Itemset
A collection of one or more items
E.g., {Milk, Bread, Diaper} <- 3-itemset
An itemset containing k items is called k-itemset
Support
Percentage of transactions containing an itemset
Indication of how frequently the items appear in the data
s=Total TransactionOccurrence(X and Y)
Association Rule
X→Y, where X and Y are itemsets
Confidence of Association Rule
Verify the Confidence of Association Rule
Indicates the number of times the if-then statements are found true
c=Occurrence(X)Occurrence(X and Y)
Is the Association Rule Good?
Check both Confidence and Support are higher than threshold
Support s>minsup
Confidence c>minconf
Example: Associative-Rule Learning
Find the support and confidence for the association rule {Milk, Diaper}→{Beer}. If both the thresholds for minsup and minconf are 60%, does this rule qualify? Why?
Support s=Total TransactionOccurrence(Milk, Diaper and Beer)=52=40% which is < 60%
Confidence c=Occurrence(Milk, Diaper)Occurrence(Milk, Diaper and Beer)=32=66.67% which is meet threshold
This rule does not qualify because it’s support failed to meet the threshold.