
Overview of GANs - Architectures
Overview of GANs - Architectures
Now I will try to explain the layers used in the Generator model and Discriminator Model, also the optimizers as well.

Discriminator Model
The Discriminator is responsible for Classification.
The Discriminator Model:
- Takes an sample as input (From real or generated)
- Produce a binary class label of real or fake(generated) as output prediction
The General Layer Pattern of Discriminator goes like that:
Where indicates repetition.
The is doing Downsampling.
Conv2D + LeakyReLU
In order to reduce the problem difficulty, we need to Downsample Using Strided Convolutions with Leaky ReLU activation. (don’t use the standard ReLU.) (Don’t use Pooling layers as well)
- Best practice is Stride
BatchNormalization
After LeakyReLU activation, we need to standardize layer outputs using BatchNormalization.
Flatten Layer
We need to flatten our image before feeding it to classifier.
Sigmoid Classifier
Sigmoid Activation is used to turn the values between 0 and 1. Since The discriminator must classify it as real (1) or fake (0), we use Sigmoid activation for the last dense layer in the Discriminator.
- 1 Node is enough for this Dense layer.
Generator Model
The Generator is responsible for Generation.
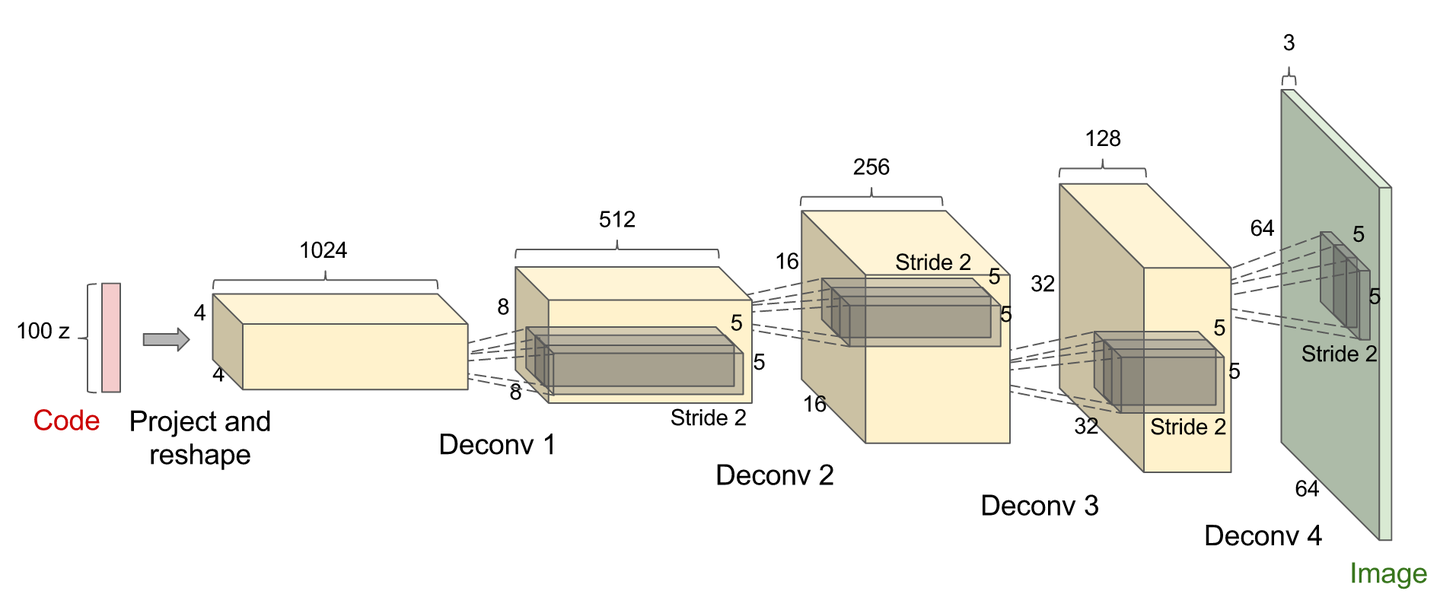
The Generator Model:
- takes a fixed-length random vector as input
- and generate a multidimensional vector space after training
- forming a compressed representation of the data distribution as output
Sometimes ReLU is used for activation function instead of LeakyReLU. (for generator model only)
The General Layer Pattern of Generator goes like that:
Where indicates repetition.
The is doing Upsampling.
Fully Connected Layer + LeakyReLU + BatchNormalization
As we mention before, the generator takes latent space as input. We need to use Dense (Fully Connected) Layer + LeakyReLU activation + BatchNormalization to construct our image.
- The Number of Nodes of the FC layer is the diamension of image you want to form. (e.g. for a 7x7 image)
- If in the Dicriminator you downsampled the image to 7x7, you must start from 7x7 and upsample it again.
- Add a Reshape Layer with specified diamension of image after BatchNormalization
Conv2DTranspose + LeakyReLU
Transposed Convolutional Layers also known as Deconvolutional Layers.
After we construct our image, use Strided Transpose Convolutional Layers to Upsample the image with Leaky ReLU activation. (don’t use the standard ReLU.)
- Best practice is Stride
BatchNormalization
After LeakyReLU activation, we need to standardize layer outputs using BatchNormalization.
Conv2D + Tanh
Tanh activation function change the output value in the range [-1,1].
- The output is a three channel image, therefore the Number of Filters for the Conv2D layer is 3.
Optimizer
Loss Function for Discriminator
since the discriminator outputs a probability for a given image between 0 and 1 for fake and real respectively, we can implement the binary cross-entropy loss function.
The discriminator model is trained like any other binary classification deep learning model.
since the discriminator outputs a probability for a given image between 0 and 1 for fake and real respectively, we can implement the binary cross-entropy loss function.
- commonly implemented as the binary cross-entropy loss function
- best practice is to use Adam as optimizer with a small learning rate and conservative momentum
Loss Function for Generator
The generator is not updated directly and there is no loss for this model. Instead, the discriminator is used to provide a learned or indirect loss function for the generator.
Compositing the Two Models
The generator model is trained via the discriminator model in a composite model architecture
- Declare a new model
- first make weights in the discriminator not trainable
- then Add discriminator into model
- then Add generator model
- lastly Compile model with binary cross-entropy loss function
- Then use Adam as optimizer with a small learning rate and conservative momentum
Reference
A Gentle Introduction to Generative Adversarial Networks (GANs)
Create Data from Random Noise with Generative Adversarial Networks
如何理解深度学习中的deconvolution networks?
