
Paper Review - Product of Experts for Visual Generation
Summary
Summary of “Product of Experts for Visual Generation”:
- Concept:
The Product of Experts (PoE) framework enables compositional visual synthesis by combining knowledge from multiple, heterogeneous sources—such as generative models, visual language models, physics simulators, and graphics engines—at inference time. - Key Applications:
- Physics-Simulator-Instructed Video Generation: Generates realistic videos from an input image and physics simulation, fusing a physics-aware expert (guaranteeing physical plausibility) and a video generation expert (ensuring visual realism).
- Graphics-Engine-Instructed Image Editing: Edits images by inserting 3D assets, combining geometric constraints (from graphics renderings) with image priors for natural results.
- Text-to-Image Generation: Decomposes complex prompts into simpler, region-specific instructions, with generative experts handling regions and a discriminative visual language model expert scoring results.
- Physics-Simulator-Instructed Video Editing: Modifies video scenes guided by physics simulations for both content and realism.
- Technical Approach:
- PoE is instantiated via sampling processes (e.g., Annealed Importance Sampling, MCMC) that interpolate between simple and complex (expert-merged) distributions.
- Uses existing models as “experts”:
- Depth-to-video and image-to-video (based on Wan2.1-I2V-14B)
- FLUX.1 for regional/depth-based generation
- Visual language models and score-based experts (e.g., VQAScore)
- Experts can be combined linearly (using interpolants) or autoregressively.
- Core Benefit:
This approach allows flexible, compositional visual synthesis grounded in multimodal knowledge—making outputs both realistic and physically/plausibly correct, leveraging domain-specific experts without retraining.
Main contribution
The main contribution of the “Product of Experts for Visual Generation” paper is:
- A unified probabilistic framework for controllable image and video generation via inference-time composition of heterogeneous pretrained experts.
Key points of their contribution:
- Product-of-Experts Composition:
They introduce a novel way to combine generative models (e.g., video diffusion), discriminative models (VLMs), rule-based systems (like physics engines), and deterministic modules (like graphics engines) at inference time—not by retraining, but by sampling from the product of expert-defined distributions or constraints. - Plug-and-Play Control:
The approach allows users to simultaneously apply multiple, possibly non-differentiable, constraints and experts (such as text prompts, physical priors, rendered layouts, etc.), yielding fine-grained, modular, and extensible controllability. - Generalized Inference Procedure:
They develop an annealed MCMC/Sequential Monte Carlo sampling strategy to efficiently generate samples consistent with all experts, regardless of the form of the expert (generative, discriminative, or deterministic). - Applications and Experiments:
They demonstrate this framework on several challenging tasks—such as physics-constrained video generation, graphics-engine-instructed image editing, and multi-expert interpolation—showcasing significantly improved adherence to specified constraints (semantics, physics, layout), and providing new ways to control and compose generative models. - Framework, Not Model:
The novelty is not a new generative model itself, but a general, extensible pipeline for leveraging a diverse set of constraints and knowledge sources at generation time, bypassing the need for retraining a single, end-to-end-absorbed model.
Related Works - Video Generation with Physical Simulators
Recent works have explored such direction typically convert physical simulator outputs into a specific type of conditional signals.
physical simulator outputs into Optical Flow
MotionCraft (NeurIPS 2024)
Paper: Motioncraft: Physics-based zero-shot video generation.
- Text-to-video generation task
- Training free. Leverage Φ-flow (PhiFlow) library for fluid simulation and optical flows to warp the noise latents in the diffusion model.
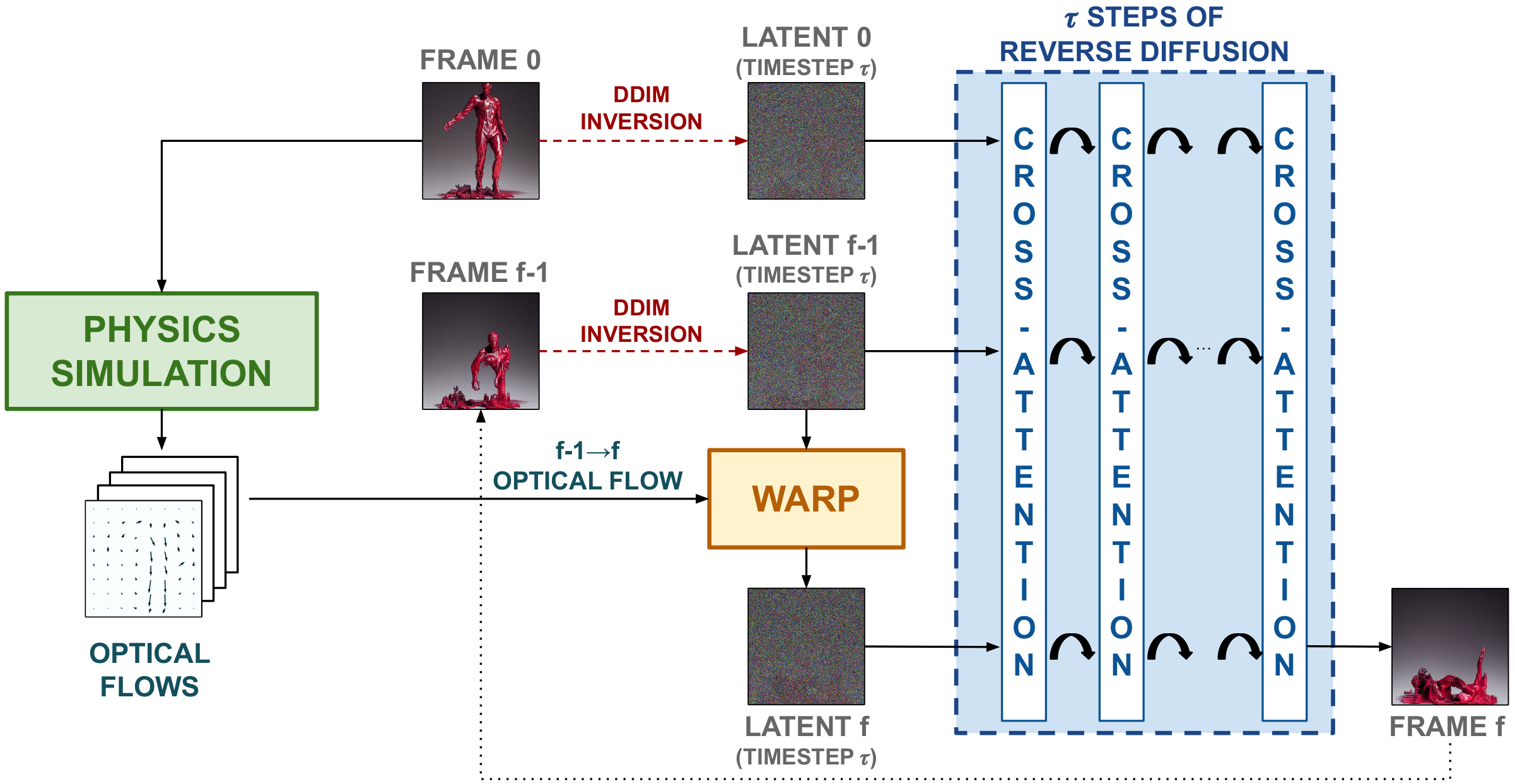
Go-with-the-flow (CVPR 2025)
Paper: Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
- Video-to-Video editing task
- fine-tune the base model. Leverage first frame + optical flow from soruce video + real time wraped noise

VLIPP (ICCV 2025)
Paper: VLIPP: Towards Physically Plausible Video Generation with Vision and Language Informed Physical Prior
- Text-to-video generation task
- First stage (Coarse-level Motion Planning) with VLM to generate a coarse, physics-aware trajectory (bounding box path) for each object, then creates a “synthetic” animation.
- In second stage (Fine-Level Motion Synthesis), It extract optical flow between consecutive frames of the synthetic video (using RAFT), generates structured noise representing motion cues for diffusion. The structured noise is fed (as a condition) into the Go-with-the-Flow image-to-video diffusion model (I2V VDM).
- During training and inference, random Gaussian noise is mixed into the structured (optical flow) noise with a tunable mixing factor. This allows the diffusion model to follow the coarse trajectory, while also having freedom to synthesize fine, realistic, and physically consistent details beyond what the VLM predicted.

physical simulator outputs into Point Tracking
DaS (SIGGRAPH 2025)
Paper: Diffusion as shader: 3d-aware video diffusion for versatile video generation control.
- Image-to-Video task
- fine-tune the CogVideo model. leverages 3D tracking videos composed of dynamic 3D point clouds as strong physical control signals
- using 3D tracking videos significantly improves the temporal and physical consistency of generated videos compared to 2D or depth-based controls


Simply rely on a single pre-trained video generation model
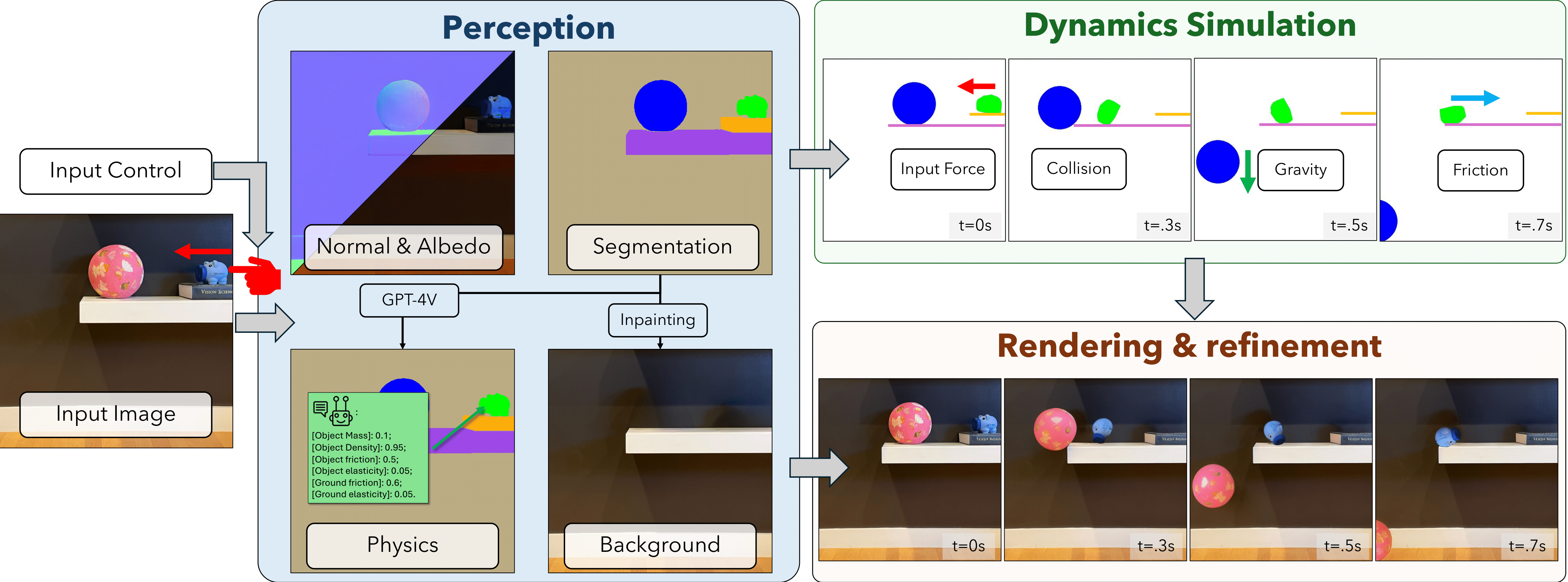
Physgen (ECCV 2024)
Paper: Physgen: Rigid-body physics- grounded image-to-video generation.
- Image-to-Video editing task
- It uses only a 2D rigid-body physics simulator operating in image space to guide the motion of segmented objects. After simulating physically plausible 2D trajectories—including collisions, friction, and user-specified forces. it rerenders and composites the moving objects back onto the scene, employing video diffusion models and relighting modules for realism. It does not model full 3D physics but achieves high-quality, controllable video by combining 2D simulation with advanced generative video techniques.
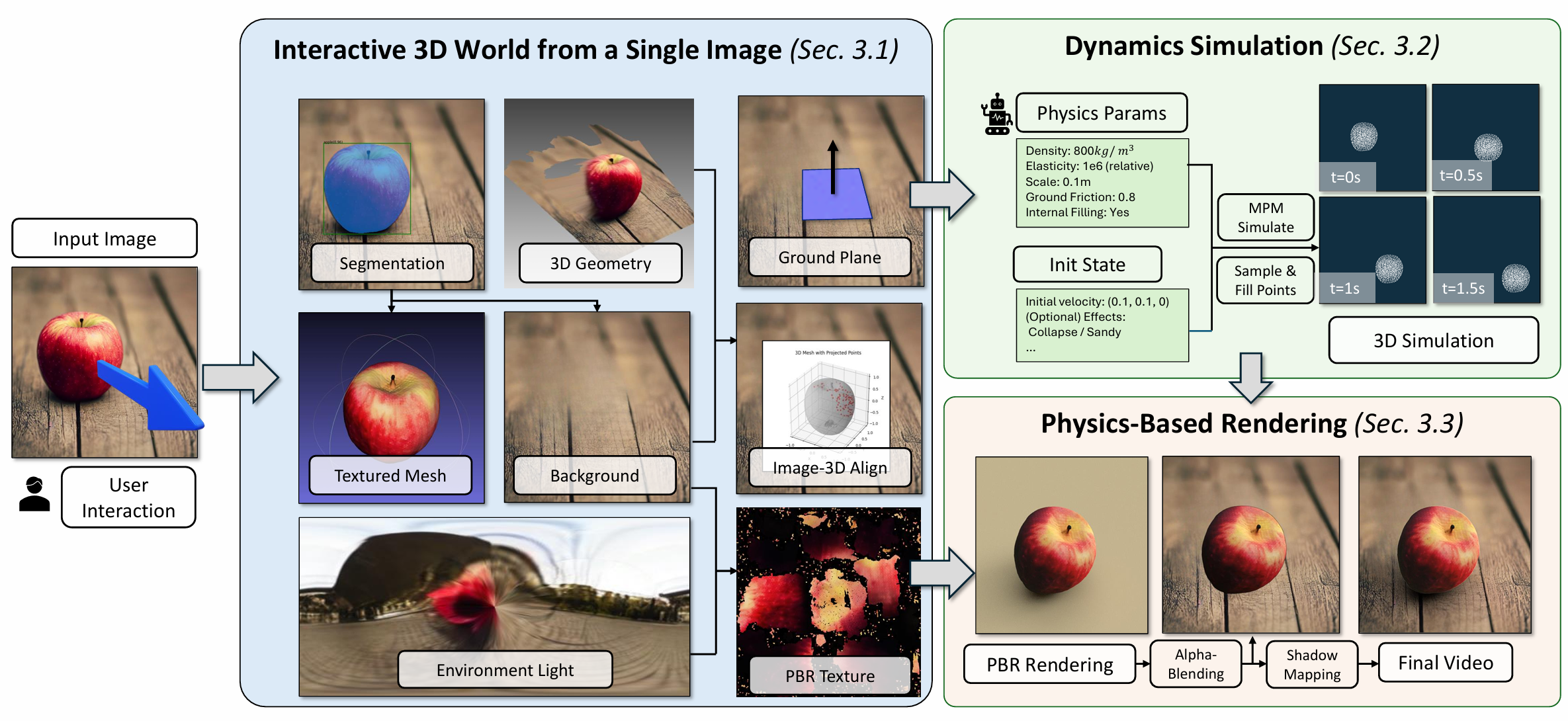
Physgen3d
Paper: Physgen3d: Crafting a miniature interactive world from a single image.
- Image-to-Video editing task
- The system reconstructs 3D scenes from single images and enables interactive physics-based simulation.
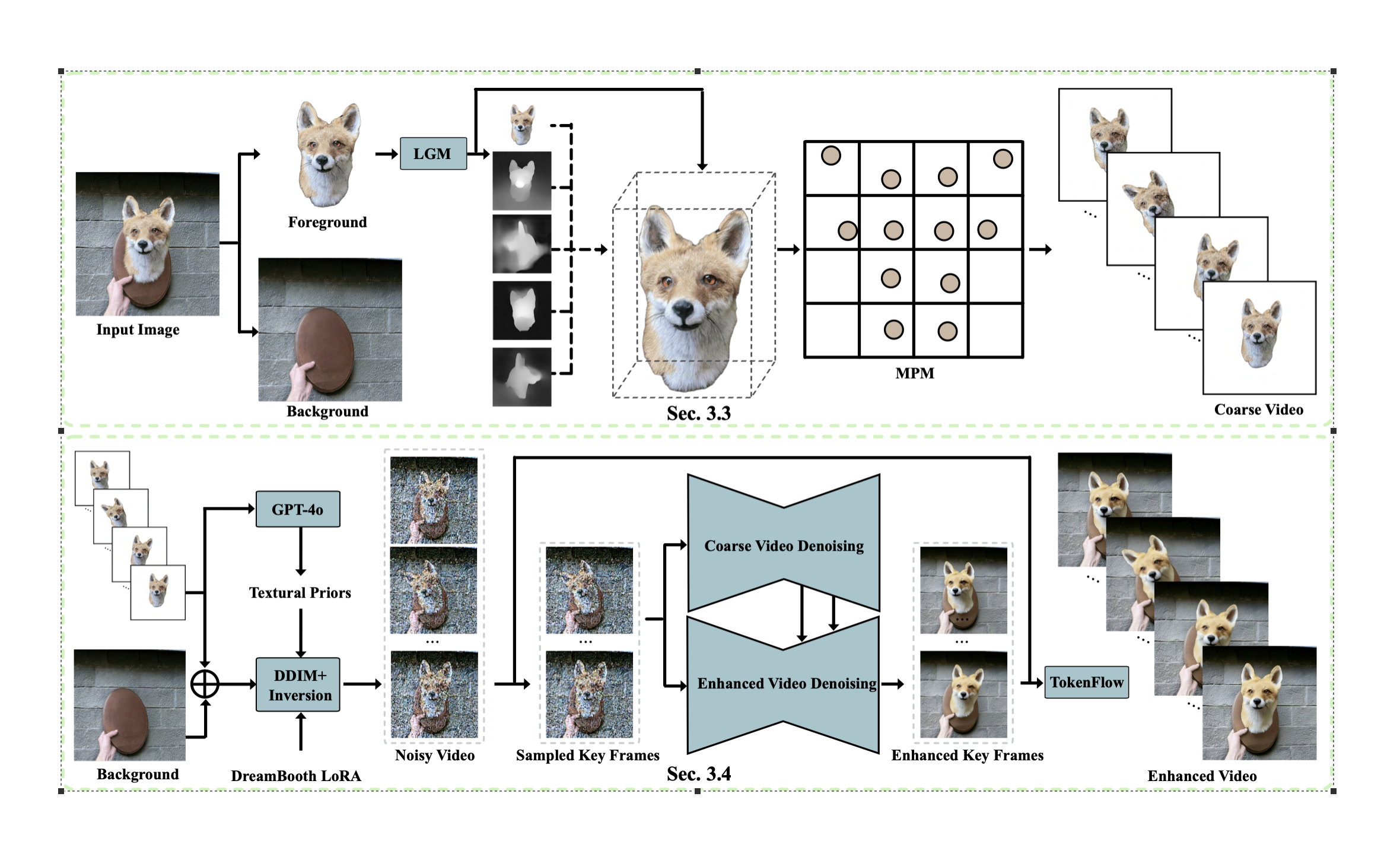
PhysMotion
Paper: PhysMotion: Physics-Grounded Dynamics From a Single Image
- Image-to-Video editing task
- Given a single image input, we introduce a novel pipeline to generate high-fidelity, physics-grounded video with 3D understanding. Our pipeline consists of two main stages: first, we perform a single view 3DGS reconstruction of segmented object from the input image, then synthesize a physics-grounded coarse object dynamics. Next, we apply a difusion-based video enhancement to produce the final enhanced video with backgrounds, enabling users to create visually compelling, physics-driven video from a single image with an applied conditional force or torque.
Method
- Product of Experts (PoE) framework for visual synthesis tasks. The framework performs inference-time knowledge composition from heterogeneous sources including visual generative models, visual language models, and sources with human-crafted knowledge such as graphics engines and physics simulators.

-
Experts Composition:
All experts (generative models, discriminative VLMs, physics and graphics engines) contribute log-probability scores or constraints for candidate samples. -
Sampling Algorithm:
- Uses an annealed Markov Chain Monte Carlo (MCMC)–style sampler with Sequential Monte Carlo (SMC) resampling.
- At each step, candidate images/videos are updated using gradients or scores from the combined product-of-experts likelihood.
- Annealing (gradually strengthening constraints or lowering temperature) helps explore feasible regions and avoid early rejection of good candidates.
-
Expert Types:
- Generative expert: e.g., video diffusion models, providing data priors.
- Discriminative experts: e.g., vision-language models, scoring semantic alignment; physics engine or graphics engine outputs add physical/layout plausibility.
- Deterministic modules: Constraints from physics or graphics engines are implemented as hard indicators or soft similarity metrics in the product.
-
Constraint Enforcing:
- For deterministic experts (like a graphics engine), constraints can be integrated as indicator functions or by scoring candidate generations based on pixel- or mask-level similarity.
- At each sample step, only candidates matching all required constraints survive.
-
Flexible Plug-and-Play:
The framework allows adding, removing, or swapping experts at inference, without retraining.
PoE Sampling with an Autoregressive Annealing Path
For most video and sequential visual tasks, the autoregressive annealing path is superior in maintaining consistency and fidelity due to its sequential, conditional generation approach. The linear path is simpler but less effective for highly dependent outputs.





