Quick intro to Machine Learning
What is Machine Learning?
Traditional Programming VS Machine Learning
Traditional Programming

- Hand-coded rules
Machine Learning

- Build model (analogous to computer program) which helps in making data-driven decisions
- No hand-coded rules
Why ML?
- Make data-driven decisions at scale
- Make decisions based onn what we have learnt over a period of time
- Automatic processes: learning patterns from data
- Try to use examples to automatically infer rules
Advantages of ML
- No human intervention
- Analyzing the data automatically and derive the final equation
- Speed
- Speed of Learning / Learning time - can take a very long time, is slow in most of cases
- Speed of Prediction / Prediction time - fast in most of the cases
- Customization / Personalization
- Produce output according to some information of particular customer
- Output is input specific (e.g. recommendation based on customer’s info)
Definition of ML
A program is said to learn from experience E with respect to task T and performance measure P, if it’s performance at tasks in T, as measured by P, improves with experience E.

T: Task
- Thing we want the model to do (pick a type of task)
- (Predicting outages for our infrastructure)
E: Experience
- How do we achieve the task. E.g. Training model by feeding dataset
- (The model will “grow” by observing patterns from various device data attributes)
P: Performance
- How good the model perform the task.
- (Measured according how accurate the model predicts outages)
Task
Types of Task:
Classification
- Discrete output (numbers of output can be any real number)
- To classify samples into categories
- Supervised
Regression
- Continuous output (numbers of output can be any real number)
- To predict a real numerical value
- Supervised
Anomaly detection
- Determine if it is an unusual pattern, different from normal behaviour
- also known as outlier detection
- Can be Supervised or Unsupervised
Clustering
- Learn inherent latent patterns, relationships and similarities among the input data points
- Unsupervised
Clustering is different to Classification.
Example showcasing the difference in Clustering, Classification and Regression
Predicting Student GPA by different tasks
- Clustering : Grouping students with similar result together to form each cluster
- Classification: Predicting student grades
- Regression : Predicting exact GPA value
Experience
Experience is basically the process of consuming a dataset that consists of data samples in order to make the model learns inherent patterns.
Also known as Training.
Performance
Performance is basically a quantitative measure to tell how well the model is performing the task.
Common measures: Accuracy, Error rate, Mis-classification rate
Flow of ML
Information sources -> Data capturing tools -> Data preprocessing -> Feature extraction -> Analysis engines -> Decision of responses

Objective of ML
To make accurate predictions of unseen samples.
ML Methods
There are different methods in ML.
- methods based on the amount of human supervision in the learn process
- Supervised Learning vs Unsupervised Learning
- methods based on the ability to learn from incremental data samples
- Batch Learning vs Online Learning
- methods based on their approach to generalization from data samples
- Instance based Learning vs model based Learning
Supervised Learning vs Unsupervised Learning
Supervised Learning
- pre-Labelled training data
- Learn an association between input and output
Unsupervised Learning
- No pre-labelled training data
- Looks for pattern
Semi-supervised Learning
- Starts with small amount of labelled data and train a model
- Then use unlabelled data to improve the model
Batch Learning vs Online Learning
Batch Learning (Offline Learning)
- The model is trained using all the training data in one go
- Once training is done, the model is deployed into production
Online Learning
- Training data is fed in mulitple incrementally
- Keeps on learning based on new data
- Used when the data characteristics changes from time to time
In Cyber-Security application we usually use with online machine learning.
E.g. Anomaly prediction / Detect email Spam (Because anomaly changes with time)
Instance based Learning vs Model based Learning
Instance based Learning
- No generalization before scoring. Only generalize for each scoring instance individually as and when seen
- Use the entire dataset as the model
- Usually have longer testing time
k-NN is an example of Instance based Learning.
Model based Learning
- Generalize the rules in form of model, even before scoring instance is seen
- After model is built, training data can be discarded
SVM is an example of Model based Learning.
ML Pipeline

Data retrieval
- Data collection from various sources
Data Preparation (data pre-processing)
- Data processing/wrangling: data cleaning, processing
- Feature extraction/engineering: find important features/attributes from the raw data
- Feature scaling/selection: normalized and scaled features to prevent ML algorithms from getting biased.
Modeling
- Feed features to a ML method and train the model
- Objective: optimize a cost function (e.g., reduce errors)
Model evaluation and tuning
- test on validation datasets (different from training data), and find out performance
- Finally Deployment and monitoring
Challenges of ML
Data Quality
Data Quality will determine the quality of our trained ML model.
- Data Quality means how reliable is our training data.
- We might need to carry data cleaning on raw data to improve quality of data
Dropping rows of missing datas columns is not a good choice because we will miss a lot of data.
Feature Extraction
80% of the time is spent on Feature Extraction. It is time-consuming.
The Selected Feature will determine the quality of our trained ML model.
- Feature is the data attribute we put in ML.
- Feature is actually the independent variable (x) in the target equation.
Feature Extraction is also known as Feature Selection.
Curse of dimensionality
- If we select too many features, it could possibly make longer training time and worse model quality.
Overfitting or Underfitting

- If we select too much features, overfitting might happen.
- Model heavily rely on training data -> bad prediction
- If we select too less features, underfitting might happen.
- Model does not rely on training data -> bad prediction
Machine Learning vs Deep Learning

Machine Learning
We do the Model Training after we manually do the Feature Extraction.
- Less Layers -> Training time much shorter
Deep Learning
Model Training involves Feature Extraction. All done by the Machine.
- More Layers -> Training time much longer
3 Stages of Machine Learning
Recall the 3 Components of ML: Task, Experience, Performance.
Representation
Basically define things in ML language.
- Define the task we want the model to do
- Define the data we would like to use for training
Evaluation
- Evaluate the model accuracy
Evaluation model - Confusion Matrix
- Form a matrix by comparing the Predicted class label with True class label.
Why it is better to use confusion matrix, rather than accuracy?
Confusion matrix provide the false positive and false negative, which help us to evaluate the model
Accuracy is not a good metric because there might be dominent.
What can we do with the false positives and negatives? are there any ways to reduce the false positives and negatives?
usually when u reduce false positive, false negative will increase. it is a trade off.
Optimization
Search for optimal model
- Adjust the parameters and give the most optimal value for evaluation function
Terminology
- Examples/Observations : instance of the data used
- Features : the set of attributes, associated with an example (e.g. IP address)
- Labels : category (classification) , real value (regression)
- Training data : data used for training learning algorithm
- Testing data : data used for testing a learning algorithm
- Unsupervised learning : a type of learning that has used no labeled data
- Supervised learning : a type of learning that has used labeled data
Training Objective
- To Develop a generalized model on the available data which will perform well on the unseen data.
- generalized model means the model can work very well when it is deployed in real applications

Cross validation (CV)

What is the difference between testing data and validation data?
Validation accuracy is to see which yielded model performs the best,
while the Testing accuracy is the metric on real-life unseen data.
Leave one out Cross Validation
Leave one out Cross Validation (Computationally expensive)
- 1000 data
- 1000 iterations:
- 999 goes into training, 1 go for validation
K-fold Cross validation
Usually K is picked 3, 5, 10.
K-fold Cross validation, for example (k = 5)
- 1000 data point
- Develop into k folds (e.g., 5 folds)
- One fold = 1000/k = 1000/5 = 200 data points in this case
- Repeat k times (5 in this case)
- Use k-1 (4 in this case) subsets for training and 1 subset for validation

A Real Example:
We first Split the data into Training Set and Testing Set, then perform CV on Training Set
4-fold CV:

In each fold, only 6000 data will be used for training, and 2000 data will be used for validation.
Performance Measure
- Often used Confusion Matrix as metric.
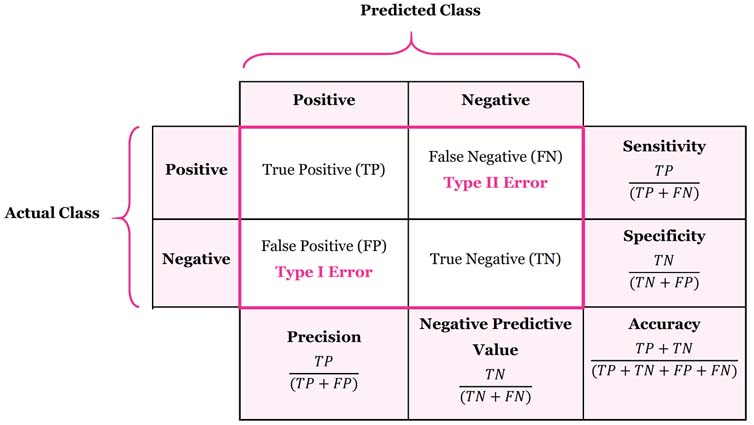
True Positive (TP): correctly classified as Positive
False positives (FP): falsely classified as Positive (So it is actually Negative but misclassified)
True negatives (TN): correctly classified as Negative
False negatives (FN): falsely classified as Negative (So it is actually Positive but misclassified)
Confusion Metrics:
- Accuracy (all correct / all) =
- Misclassification (all incorrect / all) =
- Precision (true positives / predicted positives) =
- Sensitivity aka Recall (true positives / all actual positives) =
- Specificity (true negatives / all actual negatives) =
Note Confusion Matrix can be extended into NxN.
For example, Detecting Phishing Email

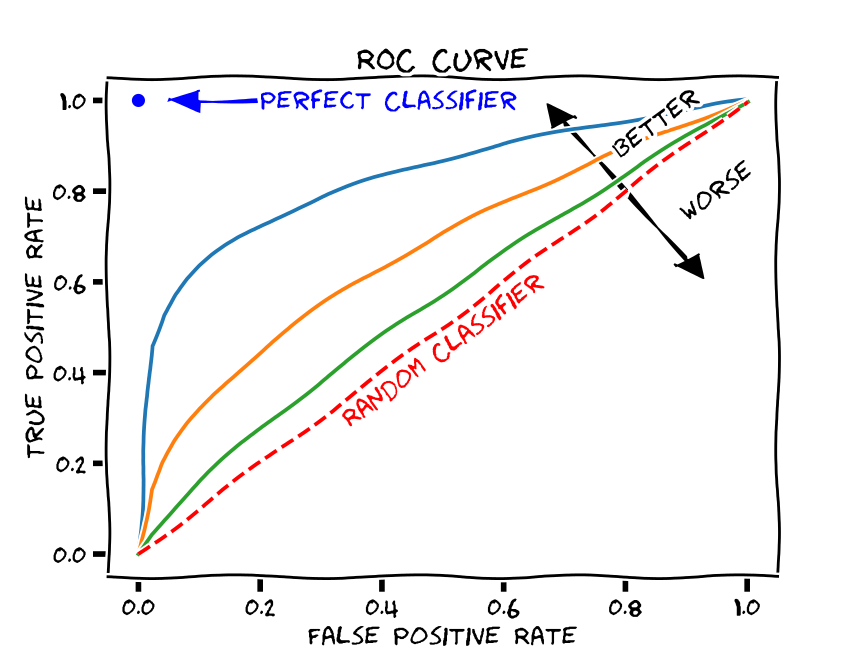
ROC Curve
A receiver operating characteristic curve, or ROC curve, is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied.